基础
前言
传统的模型训练中,迭代计算只能利用当前进程所在主机上的所有硬件资源,可是单机扩展性始终有限。而目前的机器学习有如下特点:
- 样本数量大:目前训练数据越来越多,在大型互联网场景下,每天的样本量可以达到百亿级别。
- 特征维度多:因为巨大样本量导致机器学习模型参数越来越多,特征维度可以达到千亿或者万亿级别。
- 训练性能要求高:虽然样本量和模型参数巨大,但是业务需要我们在短期内训练出一个优秀的模型来验证。
因此,单机面对海量数据和巨大模型时是无能为力的,有必要把数据或者模型分割成为多分,在多个机器上借助不同主机上的硬件资源进行训练加速。
并行机制
数据并行
- 不同的节点/node/worker使用不同的数据进行计算,在数据层面进行分割实现并行,实现相对简单
- 依据分布式的结构可以分为有中心节点和无中心节点两种
- 限制:
- 超过某一个点之后,每个GPU的batch size变得太小,这降低了GPU的利用率,增加了通信成本;
- 可使用的最大设备数就是batch size,这限制了可用于训练的加速器数量。
模型并行
- 在模型层面进行拆分,不同节点存储模型的不同部分
- 一般是在层内拆分,各个节点同时计算相同样本
Transformers并行
自Transformers提出后,现在的语言模型基本都是在Transformers的基础上得到,Transformers中主要是Attention和MLP,适合做模型并行。
MLP切分
AB是两个MLP,在列的方向切A,在行的方向切B,可以使得这两个MLP的计算过程中不需要同步,只在计算完成后才需要同步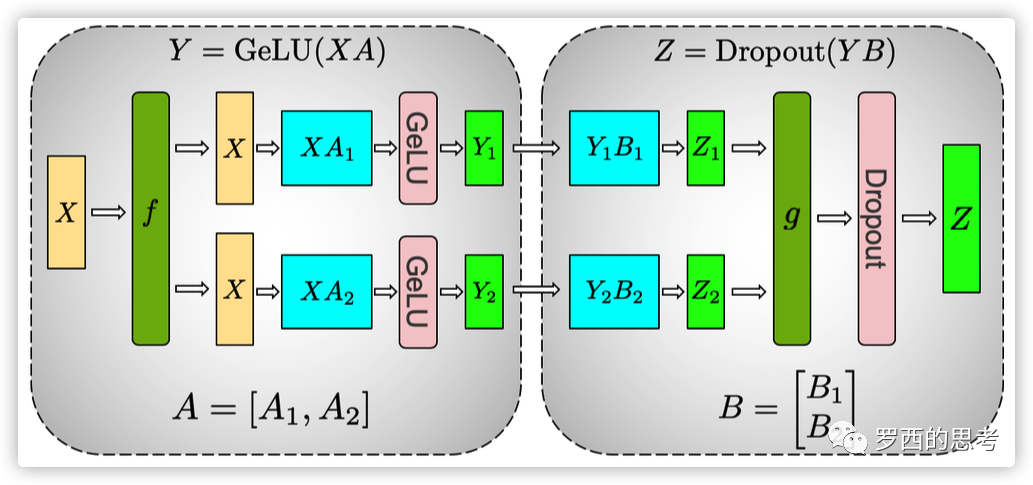
self attention切分
多头注意力固有并行性,让每个GPU计算一个或若干个头,后面的MLP则相应的按照行进行切分,在最后进行一次同步。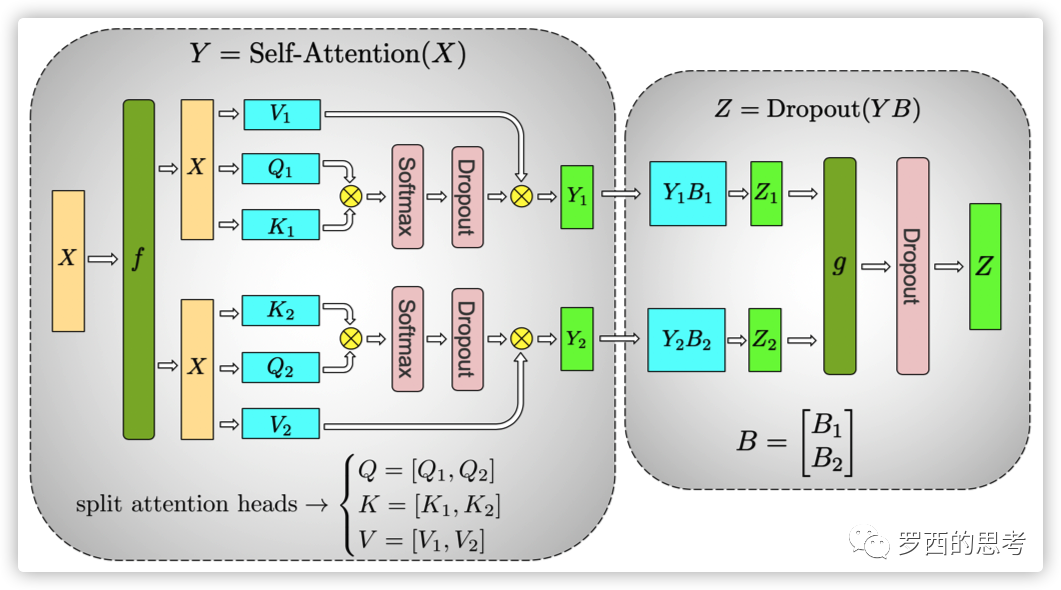
流水线并行
- 将深度学习网络看成流水线,每一层是一级
- 不同节点计算不同的层,在层的层面进行拆分
- 既可以看成模型并行也可以看成数据并行,因为不同节点保存的模型不同,相同时间计算的样本也不同
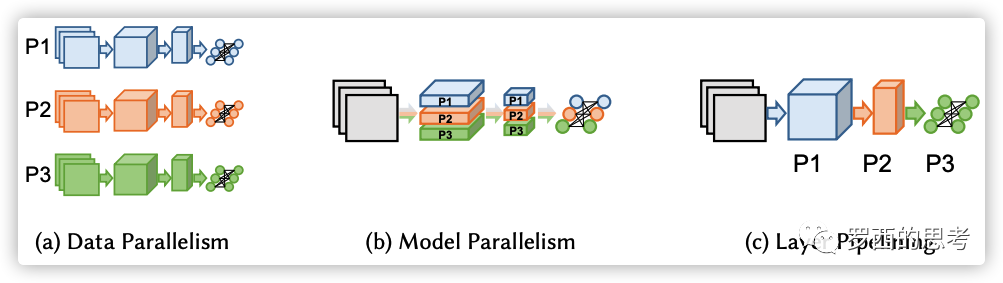
不同的并行策略更适合不同的场景:
- 网络属性也影响:卷积层参数少,更适合数据并行,全连接层参数量大,更适合模型并行
- 模型并行更多用在节点内的拆分
- 流水线并行用在节点外拆分
- 数据并行进一步扩展规模
通信
通信机制
不同GPU之间的数据、梯度、信息传递
Share memory
共享内存,只有同一个节点内的GPU才可以
Message passing
不同节点之间用消息(比如基于 TCP/IP 或者 RDMA)进行传递/通信,这样容易扩展,可以进行大规模训练。
- Client-Server 架构: 一个 server 节点协调其他节点工作,其他节点是用来执行计算任务的 worker。
- Peer-to-Peer 架构:每个节点都有邻居,邻居之间可以互相通信。
术语
MPI
- (Message Passing Interface) 是一种可以支持点对点和广播的通信协议,具体实现的库有很多,使用比较流行的包括 Open Mpi, Intel MPI 等等。
- 基于进程的并行环境
异步 vs 同步
- 同步指的是所有的设备都是采用相同的模型参数来训练,等待所有设备的mini-batch训练完成后,收集它们的梯度然后取均值,然后执行模型的一次参数更新。可以更快地进行一个收敛。但容易受木桶效应拖累。
- 异步训练中,各个设备完成一个mini-batch训练之后,不需要等待其它节点,直接去更新模型的参数,这样总体会训练速度会快很多。但是可能陷入次优解。
参数服务器
是一种client-server架构。和MapReduce不同在于 Parameter server 可以是异步的,MapReduce只有等所有map都完成了才能做reduce操作。
适合的是高维稀疏模型训练,它利用的是维度稀疏的特点,每次 pull or push 只更新有效的值。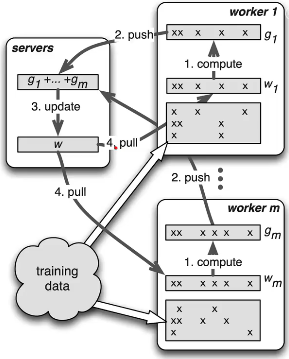
- 优势:
- 劣势:
- 确定工作者与参数服务器的正确比例:如果使用一个参数服务器,它可能会成为网络或计算瓶颈。如果使用多个参数服务器,则通信模式变为“All-to-All”,这可能使网络饱和。
- 处理程序复杂性:参数服务器的概念较多,这通常导致陡峭的学习曲线和大量的代码重构,压缩了实际建模的时间。
- 硬件成本: 参数服务器的引入也增加了系统的硬件成本。
Ring-Allreduce
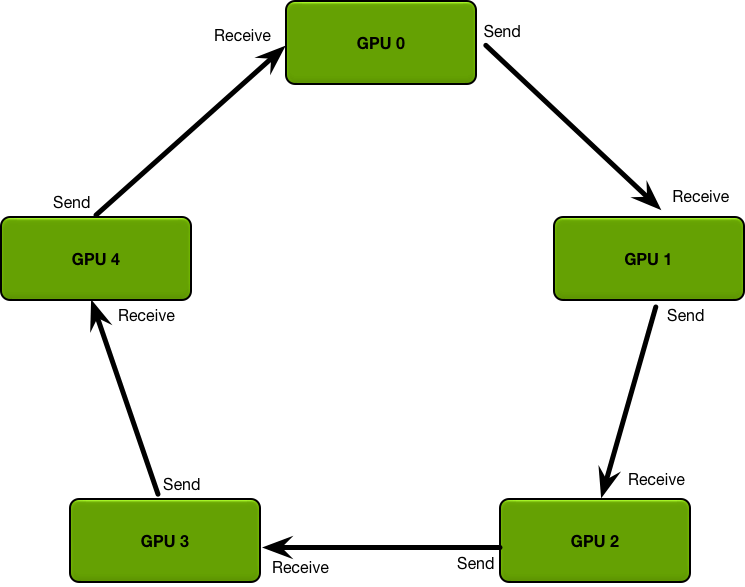
特点
- Ring Allreduce 算法使用定义良好的成对消息传递步骤序列在一组进程之间同步状态(在这种情况下为张量)。
- Ring-Allreduce 的命名中 Ring 意味着设备之间的拓扑结构为一个逻辑环形,每个设备都应该有一个左邻和一个右邻居,且本设备只会向它右邻居发送数据,并且从它的左邻居接受数据。
- Ring-Allreduce 的命名中的 Allreduce 则代表着没有中心节点,架构中的每个节点都是梯度的汇总计算节点。
- 此种算法各个节点之间只与相邻的两个节点通信,并不需要参数服务器。因此,所有节点都参与计算也参与存储,也避免产生中心化的通信瓶颈。
- 相比PS架构,Ring-Allreduce 架构是带宽优化的,因为集群中每个节点的带宽都被充分利用。
- 在ring-allreduce 算法中,每个 N 节点与其他两个节点进行 2 * (N-1) 次通信。在这个通信过程中,一个节点发送并接收数据缓冲区传来的块。在第一个 N - 1 迭代中,接收的值被添加到节点缓冲区中的值。在第二个 N - 1 迭代中,接收的值代替节点缓冲区中保存的值。百度的文章证明了这种算法是带宽上最优的,这意味着如果缓冲区足够大,它将最大化地利用可用的网络。
- 在深度学习训练过程中,计算梯度采用BP算法,其特点是后面层的梯度先被计算,而前面层的梯度慢于后面层,Ring-allreduce架构可以充分利用这个特点,在前面层梯度计算的同时进行后面层梯度的传递,从而进一步减少训练时间。
- Ring架构下的同步算法将参数在通信环中依次传递,往往需要多步才能完成一次参数同步。在大规模训练时会引入很大的通信开销,并且对小尺寸张量(tensor)不够友好。对于小尺寸张量,可以采用批量操作(batch)的方法来减小通信开销。
综上所述,Ring-based AllReduce 架构的网络通讯量如果处理适当,不会随着机器增加而增加,而仅仅和模型 & 网络带宽有关,这针对参数服务器是个巨大的提升。
策略
- 首先是scatter-reduce,scatter-reduce 会逐步交换彼此的梯度并融合,最后每个 GPU 都会包含完整融合梯度的一部分,是最终结果的一个块。
- 然后是allgather。GPU 会逐步交换彼此不完整的融合梯度,最后所有 GPU 都会得到完整的最终融合梯度。
常用概念
- local rank:就是分配给某一台计算机上每个执行训练的唯一编号(也可以认为是进程号或者GPU设备的ID号),范围是 0 到 n-1,其中 n 是该计算机上GPU设备的数量。
- rank:代表分布式任务里的一个执行训练的唯一全局编号(用于进程间通讯)。Rank 0 通常具有特殊的意义:它是负责此同步的设备。
- world_size:进程总数量,会等到所有world_size个进程就绪之后才会开始训练。
常见操作
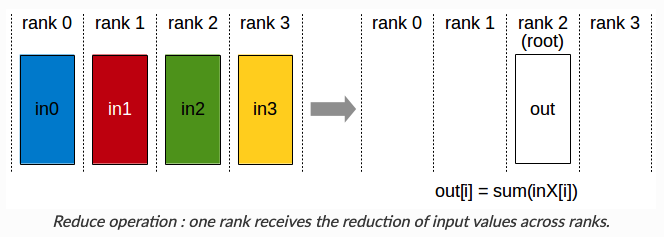
Reduce
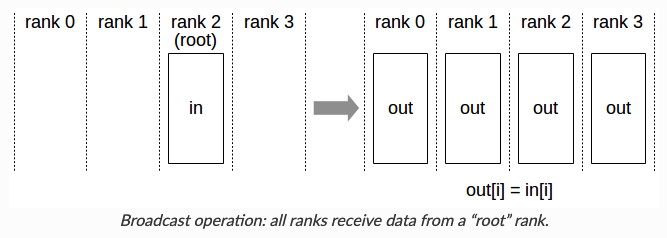
Broadcast
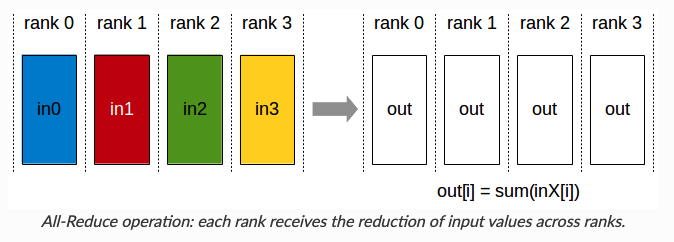
AllReduce
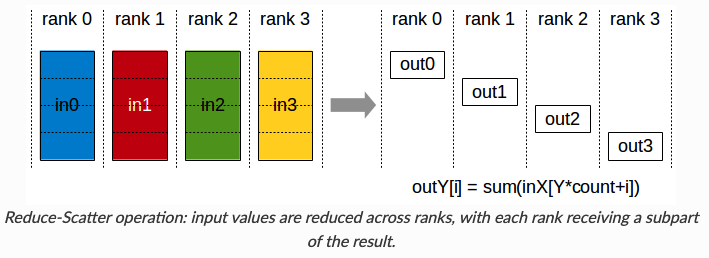
AllGather
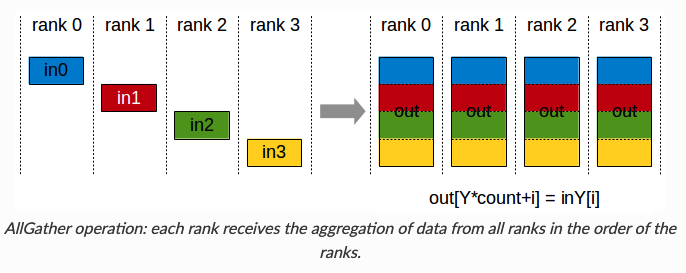
ReduceScatter
重要框架
pytorch
特点优势:
- 使用简单
- 数据并行
DataParallel
特点:
- 单机多卡
- 数据并行
- 单进程多线程
- tree-all-reduce
- 效率低,实现非常简单,适合小模型单机多卡场景
- 瓶颈在于需要其中一个主卡做同步
from torch.nn import DataParallel
device = torch.device("cuda")
model = MyModel()
model = model.to(device)
model = DataParallel(model)DistributedDataParallel
特点:
- 数据并行
- 多进程
- Ring-Reduce
- 效率高,实现简单,适用于各种场景,pytorch原生
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.utils.data.distributed import DistributedSampler
from torch.utils.data import DataLoader
gpu_list = [0,1,2,3] # 假设这个 Worker 用 0-3 号共 4 张卡
device = torch.device(f"cuda:{gpu_list[0]}") # 这里注意这个 0
# 首先看模型
model = MyModel()
model = model.to(device)
model = DDP(model, device_ids=device_ids) # 前面只能放到 list 中的第 0 个 GPU 上,然后这里再分发到其他 device 上
# 如果model没梯度就不能放DDP
optimizer = optim.SGD(model.parameters(), lr=0.001)
# 然后看数据集
dataset = MyDataset()
sampler = DistributedSampler(dataset)
loader = DataLoader(dataset, sampler=sampler, batch_size=...)# exmaple1: 1 node, 4 GPUs per node (4GPUs)
python -m torch.distributed.launch --nproc_per_node=4 main.py
# exmaple2: 2 node, 8 GPUs per node (16GPUs)
# 需要在两台机器上分别运行脚本
# 注意细节:node_rank master 为 0
# 机器1
python -m torch.distributed.launch \
--nproc_per_node=8 \
--nnodes=2 \
--node_rank=0
--master_addr="master的ip" \
--master_port=xxxxx \
YourScript.py
# 机器2
python -m torch.distributed.launch \
--nproc_per_node=8 \
--nnodes=2 \
--node_rank=1 \
--master_addr="master的ip" \
--master_port=xxxxx \
YourScript.pytorchrun
新的实现方式,使用torchrun代替torch.distributed.launch启动,包含torch.distributed.launch所有功能,同时:
- worker的rank和world_size将被自动分配
- 通过重新启动所有workers来处理workers的故障
- 允许节点数目在最大最小值之间有所改变 即具备弹性
Horovod
Horovod 是Uber于2017年发布的一个易于使用的高性能的分布式训练框架,支持TensorFlow,Keras,PyTorch和MXNet。Horovod 在百度的RingAllReduce 上进行了扎实的工程实现,使得它受到了更多的关注。它最大的优势在于对 RingAllReduce 进行了更高层次的抽象,使其支持多种不同的框架。同时引入了 Nvidia NCCL,对 GPU 更加友好。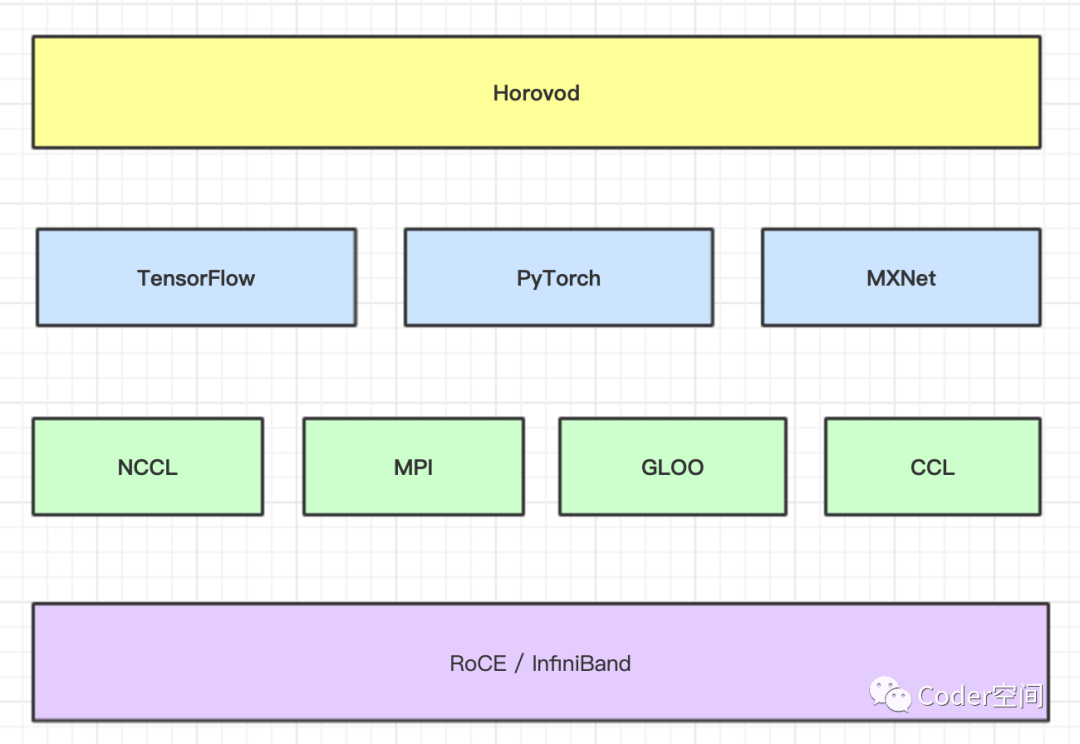
机制
- 数据并行
- RingAllReduce
- 只能用CLI命令horovodrun 来启动,如:horovodrun -np 4 -H localhost:4 python train.py
优势:
- 支持众多热门框架
- 使用较为简单
- 优化网络通信,提高集群间的通信效率
流程
- 导入库:
- import horovod.*** as hvd
- 引入底层C++程序
- hvd.init() 初始化:让并行进程们可以知道自己被分配的 rank / local rank 等信息
- 数据集处理:
- 对数据进行分片,保证每个GPU进程训练的数据集是不一样的。
- Horovod提供shuffle功能,为了让不同节点顺序拿到数据子集,深度学习框架(pytorch)的shuffle要设为False
- 广播:
- 通过hvd.callbacks.BroadcastGlobalVariablesCallback(0)使得rank 0 上的所有参数只在 rank 0 初始化,然后广播给其他节点,以实现参数一致性初始化。
- 优化器配置:
- 将原始优化器传入hvd.DistributedOptimizer,计算时候,依然由传入的原始优化器做计算。
- 在得到计算的梯度之后,调用 hvd.allreduce 或者 hvd.allgather 来计算。
- 最后实施这些平均之后的梯度。从而实现整个集群的梯度归并操作。
运行原理
horovodrun
示例:
- 单机:horovodrun -np 4 -H localhost:4 python ****.py
- 多机:horovodrun -np 16 -H server1:4,server2:4,server3:4,server4:4 python ****.py
- -np 指的是进程的数量,localhost:4表示localhost节点上4个GPU
开局准备
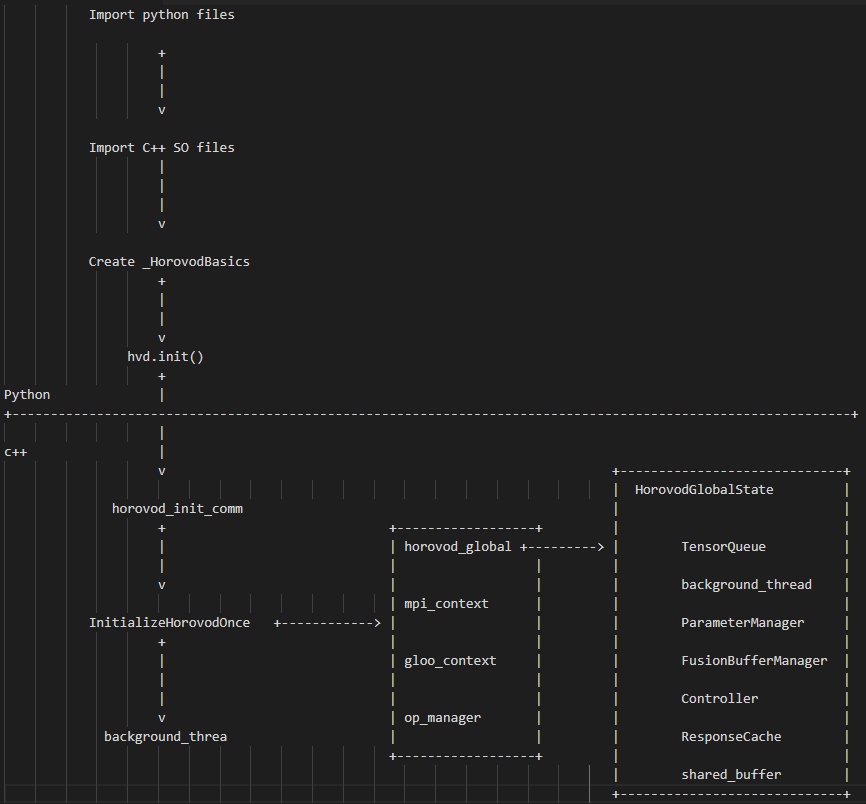
导入so文件
SO库 就是 horovod 中 C++ 代码编译出来的结果
horovod目录下给每种框架准备了一个子文件夹,在torch和tensorflow文件夹下有so文件
- 如tensorflow目录:
total 293M drwxrwsr-x 6 jovyan users 4.0K Aug 9 11:41 . drwxrwsr-x 13 jovyan users 4.0K Aug 9 11:41 .. -rw-r--r-- 1 jovyan users 2.4K Aug 9 11:40 compression.py drwxr-sr-x 3 jovyan users 4.0K Aug 9 11:41 data -rw-r--r-- 1 jovyan users 8.4K Aug 9 11:40 elastic.py -rw-r--r-- 1 jovyan users 8.2K Aug 9 11:40 functions.py -rw-r--r-- 1 jovyan users 5.8K Aug 9 11:40 gradient_aggregation_eager.py -rw-r--r-- 1 jovyan users 12K Aug 9 11:40 gradient_aggregation.py -rw-r--r-- 1 jovyan users 45K Aug 9 11:40 __init__.py drwxrwsr-x 2 jovyan users 4.0K Aug 8 14:08 .ipynb_checkpoints drwxr-sr-x 3 jovyan users 4.0K Aug 9 11:41 keras -rwxr-xr-x 1 jovyan users 293M Aug 9 11:40 mpi_lib.cpython-39-x86_64-linux-gnu.so -rw-r--r-- 1 jovyan users 22K Aug 9 11:40 mpi_ops.py drwxr-sr-x 2 jovyan users 4.0K Aug 9 11:41 __pycache__ -rw-r--r-- 1 jovyan users 2.8K Aug 9 11:40 sync_batch_norm.py -rw-r--r-- 1 jovyan users 1.5K Aug 9 11:40 util.py - torch目录:
total 279M drwxrwsr-x 7 jovyan users 4.0K Aug 9 11:41 . drwxrwsr-x 13 jovyan users 4.0K Aug 9 11:41 .. -rw-r--r-- 1 jovyan users 2.4K Aug 9 11:40 compression.py drwxr-sr-x 3 jovyan users 4.0K Aug 9 11:41 elastic -rw-r--r-- 1 jovyan users 10K Aug 9 11:40 functions.py -rw-r--r-- 1 jovyan users 3.2K Aug 9 11:40 __init__.py drwxrwsr-x 2 jovyan users 4.0K Aug 8 16:56 .ipynb_checkpoints drwxr-sr-x 3 jovyan users 4.0K Aug 9 11:41 mpi_lib drwxr-sr-x 3 jovyan users 4.0K Aug 9 11:41 mpi_lib_impl -rwxr-xr-x 1 jovyan users 279M Aug 9 11:41 mpi_lib_v2.cpython-39-x86_64-linux-gnu.so -rw-r--r-- 1 jovyan users 47K Aug 9 11:41 mpi_ops.py -rw-r--r-- 1 jovyan users 27K Aug 9 11:41 optimizer.py drwxr-sr-x 2 jovyan users 4.0K Aug 9 11:41 __pycache__ -rw-r--r-- 1 jovyan users 8.7K Aug 9 11:41 sync_batch_norm.py
- 如tensorflow目录:
TensorFlow和pytorch会通过不同的方式导入so文件:
TensorFlow中:
def _load_library(name): # Loads a .so file containing the specified operators. try: MPI_LIB = _load_library('mpi_lib' + get_ext_suffix())pytorch中:
try: from horovod.torch import mpi_lib_v2 as mpi_lib一些其它信息的导入
程序通过mpi_lib或MPI_LIB 获得C++接口
初始化配置
初始化 _HorovodBasics,然后从 _HorovodBasics 内获取各种函数,变量和配置
_basics = _HorovodBasics(__file__, 'mpi_lib_v2')
class HorovodBasics(object):
"""Wrapper class for the basic Horovod API."""
def __init__(self, pkg_path, *args):
full_path = util.get_extension_full_path(pkg_path, *args)
self.MPI_LIB_CTYPES = ctypes.CDLL(full_path, mode=ctypes.RTLD_GLOBAL)hvd.init() 初始化
将horovod 管理的所有状态都传到 hvd 对象中
def init(self, comm=None): """A function that initializes Horovod. """ atexit.register(self.shutdown) if not isinstance(comm, list): mpi_built = self.MPI_LIB_CTYPES.horovod_mpi_built() from mpi4py import MPI if MPI._sizeof(MPI.Comm) == ctypes.sizeof(ctypes.c_int): MPI_Comm = ctypes.c_int else: MPI_Comm = ctypes.c_void_p self.MPI_LIB_CTYPES.horovod_init_comm.argtypes = [MPI_Comm] comm_obj = MPI_Comm.from_address(MPI._addressof(comm)) self.MPI_LIB_CTYPES.horovod_init_comm(comm_obj) else: comm_size = len(comm) self.MPI_LIB_CTYPES.horovod_init( (ctypes.c_int * comm_size)(*comm), ctypes.c_int(comm_size))此处会调用C++接口,通过C++程序执行
horovod_init_comm:
- 调用 MPI_Comm_dup 获取一个 Communicator,这样就有了和 MPI 协调的基础。
- 然后调用 InitializeHorovodOnce。
InitializeHorovodOnce:
- 依据是否编译了 mpi 或者 gloo,对各自的 context 进行处理,为 globalstate 创建对应的 controller;
- 启动了后台线程 BackgroundThreadLoop 用来在各个worker之间协调
HorovodGlobalState:
- 在 C++ 世界,HorovodGlobalState 起到了集中管理各种全局变量的作用。
- HorovodGlobalState 在 horovod 中是一个全局变量,其中的元素可以供不同的线程访问。HorovodGlobalState 在加载 C++ 的代码时候就已经创建了,同时创建的还有各种 context(mpi_context, nccl_context, gpu_context)。
- controller 管理总体通信控制流
- tensor_queue 会处理从前端过来的通信需求(allreduce,broadcast 等);
数据部分
- 训练的数据需要放置在任何节点都能访问的地方。
- 其次,Horovod 需要对数据进行分片处理,需要在不同机器上按Rank进行切分,以保证每个GPU进程训练的数据集是不一样的。
- 数据集本体需要出于数据并行性的需求而被拆分为多个分片,Horovod的不同工作节点都将分别读取自己的数据集分片。
pytorch示例:
# Horovod: use DistributedSampler to partition the training data.
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset, num_replicas=hvd.size(), rank=hvd.rank())
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=args.batch_size, sampler=train_sampler, **kwargs)
hvd.size():# GPU总数
hvd.rank():# GPU序号
# 也可以不使用pytorch的DistributedSampler,而自己设计规则划分,只要DataLoader拿到不同的符合条件的数据集就可以
'shuffle': False广播
- 通过hvd.callbacks.BroadcastGlobalVariablesCallback(0)使得rank 0 上的所有参数只在 rank 0 初始化,然后广播给其他节点,以实现参数一致性初始化。
底层调用了 MPI 函数真正完成了功能。class BroadcastGlobalVariablesCallbackImpl(object): def __init__(self, backend, root_rank, device='', *args): def on_batch_end(self, batch, logs=None): hvd.broadcast_variables(self.model.variables,root_rank=self.root_rank) hvd.broadcast_variables(self.model.optimizer.variables(),root_rank=self.root_rank)def broadcast(tensor, root_rank, name=None, ignore_name_scope=False): return MPI_LIB.horovod_broadcast(tensor, name=name, root_rank=root_rank, ignore_name_scope=ignore_name_scope)
示例
pytorch
import horovod.torch as hvd
from torch.utils.data.distributed import DistributedSampler
from torch.utils.data import DataLoader
hvd.init()
torch.cuda.set_device(hvd.local_rank())
# device = torch.device(f"cuda:{hvd.local_rank()}")
train_dataset = MyDataset()
train_sampler = DistributedSampler(train_dataset, num_replicas=hvd.size(), rank=hvd.rank())
train_loader = DataLoader(train_dataset, batch_size=args.batch_size, sampler=train_sampler, **kwargs)
# Horovod: scale learning rate by the number of GPUs.
model = MyModel()
model = model.to(device)
optimizer = optim.SGD(model.parameters(), lr=args.base_lr * hvd.size(),momentum=args.momentum, weight_decay=args.wd)
# Horovod: wrap optimizer with DistributedOptimizer.
optimizer = hvd.DistributedOptimizer(optimizer, named_parameters=model.named_parameters())
# Horovod: broadcast parameters & optimizer state.
hvd.broadcast_parameters(model.state_dict(), root_rank=0)
hvd.broadcast_optimizer_state(optimizer, root_rank=0)tensorflow
import tensorflow as tf
import horovod.tensorflow as hvd
# Initialize Horovod
hvd.init()
# Pin GPU to be used to process local rank (one GPU per process)
config = tf.ConfigProto()
config.gpu_options.visible_device_list = str(hvd.local_rank())
# Build model...
loss = ...
opt = tf.train.AdagradOptimizer(0.01 * hvd.size())
# Add Horovod Distributed Optimizer
opt = hvd.DistributedOptimizer(opt)
# Add hook to broadcast variables from rank 0 to all other processes during
# initialization.
hooks = [hvd.BroadcastGlobalVariablesHook(0)]
# Make training operation
train_op = opt.minimize(loss)
# Save checkpoints only on worker 0 to prevent other workers from corrupting them.
checkpoint_dir = '/tmp/train_logs' if hvd.rank() == 0 else None
# The MonitoredTrainingSession takes care of session initialization,
# restoring from a checkpoint, saving to a checkpoint, and closing when done
# or an error occurs.
with tf.train.MonitoredTrainingSession(checkpoint_dir=checkpoint_dir,config=config,hooks=hooks) as mon_sess:
while not mon_sess.should_stop():
# Perform synchronous training.
mon_sess.run(train_op)Keras
from tensorflow import keras
import tensoflow.keras.backend as K
import tensorflow as tf
import horovod.tensorflow.keras as hvd
#Initialize Horovod
hvd.init()
#Pin GPU to be used
config = tf.ConfigProton()
config.gpu_options.visible_device_list=str(hvd.local_rank)
K.set_session(tf.Session(config=config))
model = ...
x_train, y_train, x_test, y_test = ...
#change lr
opt = keras.optimizers.Adadelta(lr=1.0 * hvd.size())
#Add Horovod Distribute Optimizer
opt = hvd.DistributedOptimizer(opt)
model.complie(loss = 'categprical_crossentropy',optimizer=opt,metrics=['accuracy'])
#Broadcast initial variable state
callbacks = [hvd.callbacks.BroadcastGlobalVaribaleCallback(0)]
model.fit(x_train,y_train,batch_size=32,callbacks=callbacks,epochs=(10 // hvd.size()),validation_data(x_test, y_test))horovod流程
- jupyterhub环境中完成开发
- 制作镜像:
- 镜像制作方式:
- jupyter镜像+多节点挂载存储卷:存储卷无法多节点挂载
- 将必要代码和环境移到/tmp中+commit jupyter镜像:
- 需要在容器中搬移文件,配置新环境;
- jupyter镜像存在ssh连接不便的问题
- 基于jupyter镜像编写dockerfile:
- 镜像制作方式:
- 启动MPIJob,完成分布式训练
- 保存训练结果:
- 保存方式:
ssh-keygen
vim authorized_keys
vim /etc/ssh/sshd_config
PermitRootLogin yes
PubkeyAuthentication yes
PasswordAuthentication yes
service ssh restart/start
horovodrun -np 4 -H localhost:2,172.17.0.3:2 python pytorch/pytorch_mnist.pyMegatron
基于 PyTorch 的分布式训练框架
特点:
- 数据并行
- 模型并行
- 流水线并行
deepspeed
微软提出的,在nvidia的apex、Megatron等等基础上整合改进而成,能够更大程度的减少内存冗余,充分利用资源,用更小的资源训练更大的模型。
特点
- 3D 并行:灵活组合数据并行、模型并行、流水线并行
- ZeRO(零冗余优化器):减少显存的冗余存储,提升显存效率
- ZeRO-Offload:通过同时利用GPU和宿主机 CPU 的计算和存储资源,可以高效训练的最大模型规模。
- 稀疏注意力 kernel:一套支持稀疏注意力计算的工具,可以极大提高稀疏注意力的计算效率
- 1 比特 Adam:通过预处理解决了梯度中的非线性依赖问题进而大幅减小了Adam优化器在通信时的开销
- 梯度累积:按顺序执行Mini-Batch,同时对梯度进行累积,累积的结果在最后一个Mini-Batch计算后求平均更新模型变量。
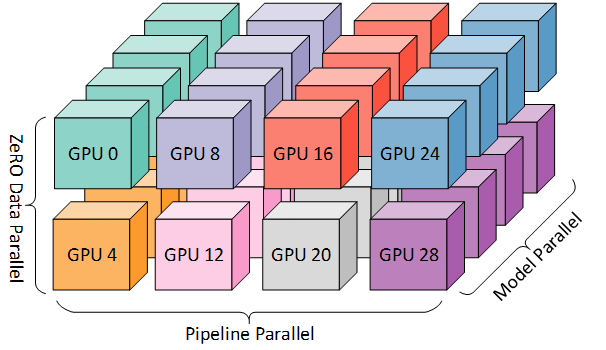
ZeRO
显存占用
显存占用分为两类:
- 模型状态:模型参数(fp16)、模型梯度(fp16)和Adam状态(fp32的模型参数备份,fp32的momentum和fp32的variance)。假设模型参数量 Φ ,则共需要 2Φ+2Φ+(4Φ+4Φ+4Φ)=4Φ+12Φ=16Φ 字节存储,可以看到,Adam状态占比 75% 。
- 其余状态:除了模型状态之外的显存占用,包括激活值(activation)、各种临时缓冲区(buffer)以及无法使用的显存碎片(fragmentation)。
其中模型状态是重点优化对象,而Adam状态又是其中的重点
优化思路-分区
数据并行的是否每个GPU上都会保存重复的内容,因此存在冗余
解决方式是对各种状态进行分区,每张卡只存1/N的模型状态量,这样系统内只维护一份模型状态。就可以极大地降低显存消耗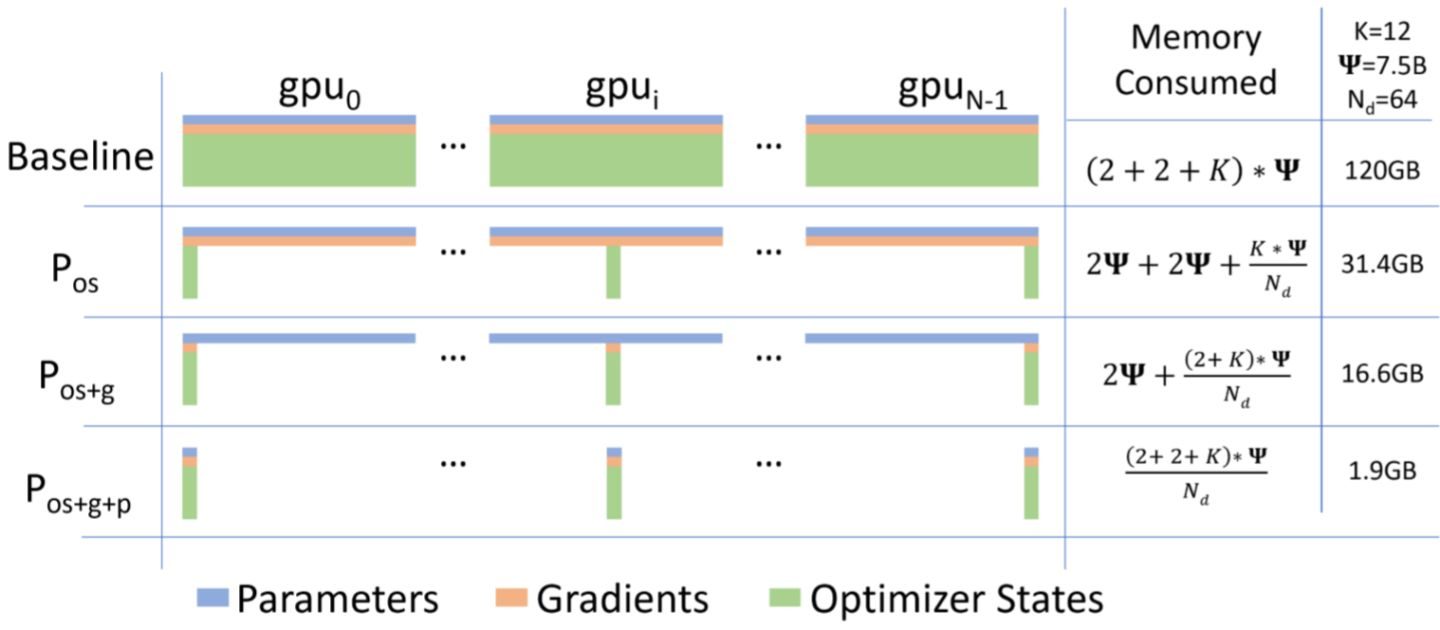
图中ZeRO-1将优化器状态分区,ZeRO-2进一步将梯度状态分区,ZeRO-3进一步将模型参数分区,因为优化器状态是大头,所以ZeRO-1就已经降低了大部分的显存消耗
另外对于其余状态:
- 激活值也可以使用分区
- 缓冲区预先固定,不动态创建;当传输数据较小时可以bucket后传输,提高效率
- 对常驻的模型状态预先分配连续显存,避免显存销毁
通信成本
分布式数据并行的通信成本为2Φ。
通过设计,ZeRO-1和ZeRO-2并不增加通信成本,ZeRO-3会增加通信成本,具体过程如下:
- 传统分布式数据并行:
- Reduce-Scatter:使得每个GPU得到一部分参数合并的梯度
- AllGather:同步参数梯度,并各自更新优化器状态,更新所有参数
- ZeRO-1:
- Reduce-Scatter:使得每个GPU得到一部分参数合并的梯度
- 每个GPU计算并更新相应的优化器状态,更新参数
- AllGather:同步参数
- ZeRO-2:
- Reduce-Scatter:
- 梯度下降的过程中一边计算梯度、一边传递梯度、一边丢弃自己不需要的梯度,使得每个GPU都只保存大约1/N的梯度
- 使得每个GPU得到一部分参数合并的梯度
- 每个GPU计算并更新相应的优化器状态,更新参数
- AllGather:同步参数
- Reduce-Scatter:
- ZeRO-3:在ZeRO-2的基础上,
- 前项传播和反向传播都需要各个GPU轮流把自己的模型参数广播出去
- 每次用完就扔
- 这样可以少存模型参数,但是增加了通信量
- 个人感觉这个改进不如用模型并行
ZeRO-Offload
思路
- 用CPU内存来保存一部分信息,以补充显存,提高训练大模型的能力
- 不能过于增加通信量
- CPU计算能力弱,不能参与过多计算
划分方式
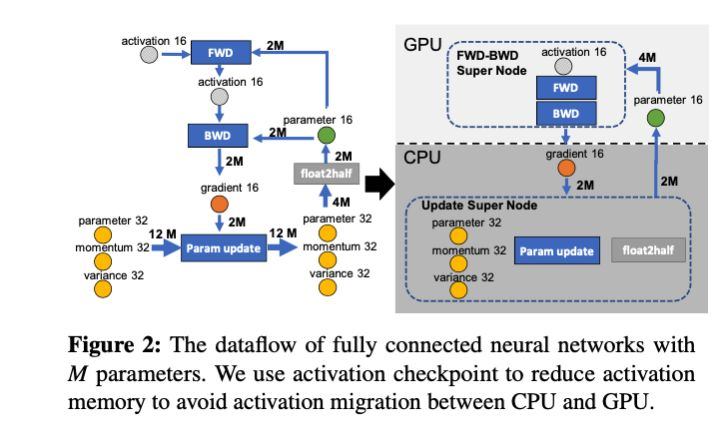
基于此种思路,ZeRO-Offload设计了如图的划分方式,其中在:
- 计算方面:
- 将前向传播和反向传播这两个计算量大的过程放在GPU
- 将参数更新和半精度处理这两个计算量小的过程放在CPU
- 存储方面:
- 将前向传播和反向传播过程中需要用到的16位参数放在显存
- 将梯度和优化器状态、参数等放在内存
- 通信方面:
- 内存向显存传递16位参数
- 显存向内存传递16位梯度
可以看出,通过这种划分,计算基本放在了GPU,存储基本放在了内存,通信量也不算大,可以说是充分发挥了各个部分的作用,各个部分都物尽其用。
通信方式
同时计算和通信还可以并行处理,GPU一边计算梯度一边offload梯度到内存,CPU一边更新参数一边swap参数到显存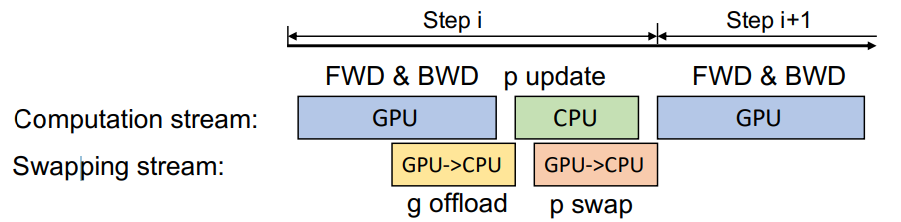
延迟参数更新
GPU的计算量/CPU的计算量大约和batchsize正相关,当batchsize较小时,GPU计算的快,CPU跟不上。
这种情况下可以使用延迟参数更新:
在完成了前n步的早期更新后,GPU计算完后空算一步,在下一步才用CPU更新上来的参数
原论文的实验未发现延迟参数更新对收敛和效果的影响。
使用方式
- 配置输入参数:
import argparse def add_argument(): parser = argparse.ArgumentParser(description=) parser.add_argument(...) parser = deepspeed.add_config_arguments(parser) args = parser.parse_args() return args args = add_argument() - 通过deepspeed.initialize()对模型等进行包装:
parameters = filter(lambda p: p.requires_grad, net.parameters()) model_engine, optimizer, trainloader, __ = deepspeed.initialize(args=args, model=net, model_parameters=parameters, training_data=trainset) - 运行命令:指定机器、模型参数文件等
deepspeed --hostfile=hostfile --include="host1:3@host2:2,3" train.py -p 2 --steps=200 --deepspeed_config=ds_config.json



