写在前面
- 推荐场景相对于图像、文本等场景来说,混沌程度更高;
- 因为图像、文本等领域的信息高度集中在单一数据中,没有过于复杂的交互逻辑,换句话说人可以很容易识别图片中有什么,理解文本的情感,所以是把人可以做好的事情交给机器去做;
- 而影响推荐的因素不胜枚举,往往只有极高情商的人可以做好推荐,所以推荐系统是去做人做不好的事情,是一种非常不同的挑战;
- 当然这种不同既决定了推荐很难做到特别好,但同时也使得人们对推荐系统的效果有更高的容忍度;推荐推得奇奇怪怪大家容易接受,但计算机视觉指鹿为马一定会被嘲讽;
推荐系统基础
基本概念
为什么需要推荐
- 信息过载:信息量大,无法有效查找到喜欢及需要的内容;
- 马太效应:头部效应明显,强者愈强;
- 目标不明确:用户很多时候没有明确的需求。
- 社会的发展趋势是建立越来越多的连接;推荐系统就是通过已有连接预测可能与人建立的连接。
推荐系统要解决
- 在数百毫秒内提供推荐结果
- 尽量离线完成各种计算,线上只保留非常少的步骤
- 采用召回、粗排、精排、重排等多层架构,保障速度和准确性
- 发掘和创造未知的需求;
推荐的方式
- 社会化推荐:朋友;
- 基于内容:利用用户、项目、环境特征,学习模型;
- 机器学习、数据驱动;
- 协同过滤:基于相似、使用交互数据;
- 用户可以齐心协力,通过不断地和平台互动,使推荐列表能够不断地过滤掉自己不感兴趣的物品,从而越来越满足自己的需求。
- 混合推荐:使用多种策略,优势互补,实际中多为混合。
影响推荐的元素
- UI&UE:即⼈机交互设计和⽤户体验设计,直接影响用户体验;
- 数据:决定信息量,决定推荐效果的上限;
- 领域知识:对业务的理解,才能设计更加合适的算法和策略,可以认为是人工先验知识,可以增加推荐系统的信息量;
- 算法:影响系统的长期效果;
用户画像
- 推荐系统训练过程中的副产品,也就是用户、项目的各种属性特征,最后以向量化的方式呈现;
- 最终用户画像的维度取决于哪些维度对于推荐有用;
相似度/距离
- 不同的距离度量方式有各自的特点,无绝对优劣,应该针对问题场景选择;
欧氏距离
- 欧式空间中的绝对距离
- 不适合隐式反馈
余弦距离
$$ sim_{uv} = cos(u,v) =\frac{u\cdot v}{|u|\cdot |v|} $$
- 向量角度距离,不满足距离定义的三角不等式
- 适用于主要考虑倾向性、情感方向,而数据量不等的场景,如摘要与文章的相似度,不同用户喜好相似度等
- 适用于显示反馈的评分数据
皮尔逊相关系数
$$ sim(u,v)=\frac{\sum_{i\in I}(r_{ui}-\bar r_u)(r_{vi}-\bar r_v)}{\sqrt{\sum_{i\in I }(r_{ui}-\bar r_u)^2}\sqrt{\sum_{i\in I }(r_{vi}-\bar r_v)^2}} $$
- 两个变量的协方差和标准差的商;
- 余弦相似度度量的是向量的绝对方向,皮尔逊相关系数度量的是随机变量变化的方向差别是正相关还是负相关
- 相较于余弦相似度,皮尔逊相关系数通过使用用户的平均分对各独立评分进行修正,减小了用户评分偏置的影响。
杰卡德(Jaccard)系数
$$ sim_{uv}=\frac{|N(u) \cap N(v)|}{|N(u)| \cup|N(v)|} $$
- 集合交集与并集的比,非常适合布尔向量;
- 适合隐式反馈数据:一般无法反映具体用户的评分喜好信息,所以常用来评估用户是否会对某物品进行打分,而不是预估用户会对某物品打多少分。
实验评价方式
离线实验、单元测试、在线实验、用户访谈依次递进。
离线实验:收集数据、制作数据集、实验与评价
- 优点:不需要有实际系统的控制权、不需要用户参与实验、速度快可以大量实验。
- 缺点:无法计算商业关心的指标、离线实验的指标与实际商业指标存在gap。
单元业务规则测试
- 对部分/单元的业务/功能进行测试,考察是否正常工作,类似于传统的软件测试;
case分析:在上线测试前选定一部分case进行验证测试,通过调用推荐服务,查看一些代表性case的效果,查看推荐效果和一些可以计算的指标;
- 重点:保住选定用户是整体的独立同分布采样,分层、随机采样
- 优点:得到很多离线测试无法得到的指标
- 缺点:成本高,效果越好需要越多用户
在线实验:AB测试,在实际环境下将用户随机分组,不同用户使用不同的推荐系统,测试效果
- 优点:获得推荐算法的实际指标
- 缺点:周期长,设计较为复杂
- 影响因素:
- 流量大小:越大越好;
- 流量分配是否均匀、分层、合理;
- 流量是否无偏:前后实验是否相互影响;
- 流量划分:
- 域:对流量进行直接划分;为了更加灵活配置流量
- 层:每一层做一个实验,各个层的划分相互正交;域和层之间可以连续嵌套;
- 桶:一个层的实验中的每一个实验组都是一个桶,每一个桶对应一组特殊的参数;用户划分要通过合适的散列函数如MD5来进行均匀划分;
- 统计效果:流量越大,统计意义越明显
用户访谈
- 在线实验的指标可能不全面,可能损害长期效果,通过用户访谈发现一些潜在问题;
评价指标
- 不同的评价指标提供不同方面的效果评价,需要根据实际需求组合选取
用户满意度
- 点击率、用户停留时间、转化率、用户评价等等,只能通过用户调查、在线测试获得。
预测准确率
- 离线评价指标,绝大多数的论文都会围绕这个指标。
- TopN推荐:准确率(Precision)、召回率(Recall),对于同一个模型或系统,两个指标相互矛盾
- $\text { Recall }=\frac{\sum_{u \in U}|R(u) \cap T(u)|}{\sum_{u \in U}|T(u)|}$
- $\text { Precision }=\frac{\sum_{u \in U}|R(u) \cap T(u)|}{\sum_{u \in U}|R(u)|}$
- 归一化折损累计增益NDCG
point-wise
- 对于一个用户,独立地给每个项目进行打分,如评分预测:RMSE(均方根误差)、MAE(绝对值误差),点击率预估等;
pair-wise
- 不关注项目的具体得分,而更多地要求将正样本排列在负样本前面;相对于point-wise可以增加数据量,因为每一个用户可以得到更多地正负样本对;
- AUC:ROC曲线下的面积;当有$M$个正例和$N$个负例时,总共有$M * N$个正负例对,当正例排在负例前时为正序贡献1,否则为逆序贡献0,如果得分相同则贡献0.5,所有的贡献和作为分子,除以总数$M * N$得到AUC值;
- BPR(Bayesian Personalized Ranking):贝叶斯个性化排序,在pair-wise正负样本对的基础上加入先验知识(如L2正则化),最大化后验概率;
覆盖率
- 对所有用户的推荐item占总item的比例,评价是否有效地覆盖长尾商品,是item提供商重点关注的指标。
- $\text { Coverage }=\frac{\left|U_{u \in \mathrm{U}} R(u)\right|}{|I|}$
- 这里未考虑不同item之间的公平性,可以用信息熵或基尼系数加以衡量
- $H=-\sum_{i=1}^{n} p(i) \log p(i)$
- $p(i)$是物品i的流行程度
- $G=\frac{1}{n-1} \sum_{j=1}^{n}(2 j-n-1) p(i_{j})$
个性化
- 不同用户推荐列表的相似程度;
- 基尼系数:推荐项目的马太效应有多严重;
多样性
- 用户的兴趣往往是广泛的,因此需要避免推荐系统的推荐过于相似,这样难以发现用户潜在兴趣点。
- $\text { Diversity }=1-\frac{\sum_{i, j \in R(u), i \neq j} s(i, j)}{\frac{1}{2}|R(u)|(|R(u)|-1)}$
新颖性
- 推荐系统应该尽量不给用户推荐用户已经有过交互过的产品,既包括在本平台交互过的,也包括在其它地方交互过的。
- 一些观点将新颖性定义为不流行程度
惊喜度
推荐用户过去没有兴趣也没有交互,但交互后会满意的产品
信任度
相同的产品,推荐方式的不同用户的反应会截然不同,例如以广告的方式呈现时用户容易反感,而告诉用户他的号朋友也在用时就更容易接受。
实时性
- 许多商品如新闻、微博具有时间限制;
- 新商品的冷启动
鲁棒性
具有抵挡攻击,反作弊的能力
商业效果
如广告的投放量
用户行为数据
显式反馈
- 用户明确对物品的喜好,包括:喜欢/不喜欢,评分等
- 信息密度大但量小,用户从浏览、点击、加购物车、购买、评分是一系列漏斗,数据量越来越小
- 对应评分预测
隐式反馈
- 不能明确用户喜好的行为,包括:浏览记录等
- 信息密度小但量大
- 对应CTR(Click Through Rate)预估
- 可以通过隐式反馈次数得到置信度,对损失函数进行加权
对比
| 角度 | 显式反馈 | 隐式反馈 |
|---|---|---|
| 用户兴趣 | 明确 | 不明确 |
| 数据量 | 较少 | 庞大 |
| 存储 | 数据库 | 分布式文件系统 |
| 正负反馈 | 都有 | 只有正反馈/单向信号 |
| 数据形式 | 主要实数 | 主要布尔 |
负样本
- 隐式反馈的信息一般提供用户感兴趣的正向信息,而模型训练还需要负向信息,因此需要对其它未交互的样本进行采样得到负样本;
随机负采样
- 思想比较直接,但是因为推荐中头部效应明显,能够学到的信息少;
- 大量的未交互项目可能只是用户未发现,作为负样本不是很合理;
热门负采样
- 越热门的项目,用户看到的概率更大,可以以更大的概率进行采样;
- 按照概率采样最后往往可以最大化表示与样本的互信息,有更好地关联性;
同类负采样
- 对一个正样本,它的同类样本相对于一般样本更有可能被交互,但是没有交互,里面有更多信息,可以加大采样频率;
浏览未交互
- 用户看到却没有点击/交互的项目有更加明显的负向信息,或者说有明确的监督信息;
实时推荐
- 信息的价值随时间衰减,所以用户的当下行为非常重要;
- 实时的层次:响应快、实时特征、实时更新模型;
- 将实时数据写入kafka中,另一侧从kafka中读取数据进行实时流计算;
- 常见流计算框架:storm、S4、streaming;
推荐系统架构
特点
- 实时响应;
- 及时、准确、全面记录用户反馈数据/信息;
- 降级;
- 监控;
- 便于策略实验;
通用架构
- 日志收集:从用户端收集各种数据信息;
- 现代推荐系统是数据驱动,数据获取是必要环节;
- 数据用途由浅入深:制作报表、数据分析、机器学习;
- 数据包括用户、项目等的静态信息和用户在使用产品的过程中产生的信息,一般通过埋点记录得到日志,整合成表格;
- 需要保证数据的正确、完整、及时
- 数据处理/机器学习:根据收集的信息进行数据处理和机器学习的任务,提供项目打分;
- 模型训练等离线,打分实时;
- 打分要明确目标;充分使用多目标信息;挖掘正向和负向信号;
- 内容发布:通过推/拉的方式将信息/项目推送到用户侧;
- 拉:用户侧调用服务或发送请求,以获取所需内容;更加实时,但是操作复杂;
- 推:内容产生后推送给订阅者/粉丝等;非实时/延迟,可用性高,冗余存储;
- 综合使用:活跃度高的用户、与作者/内容亲密度高的用户更多地推;活跃度低、亲密度低的用户更多地拉;
- 监控:监测系统运行的重要指标,确保系统的稳定和安全;
架构分层
| 分层 | 离线 | 近线 | 在线 |
|---|---|---|---|
| 特点 | 不使用实时数据,不提供实时服务 | 使用实时数据,不保证实时服务 | 使用实时数据,保证实时服务 |
| 优势 | 可以批量处理大量数据;没有响应时间限制 | 使用实时信息且响应时间要求不严格 | 信息全面;只进行必要计算 |
| 约束 | 静态信息,无法及时应对用户、环境变化 | 保证响应时间和稳定性 | |
| 举例 | 协同过滤、数据处理/挖掘、模型训练等可以离线的尽可能离线 | 根据实时数据对模型进行在线训练/更新 | 排序打分;重排;过滤等逻辑;互动规则 |
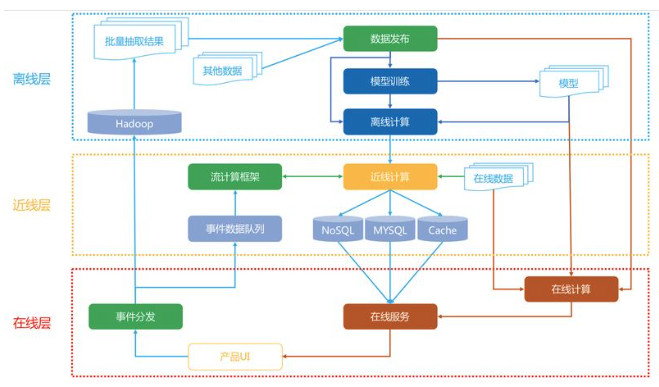
存储
- 数据类型:
- 稀疏型:ID特征、类别特征;
- dense/稠密型:embedding;
- 正排:一般用用户ID、项目ID,得到用户、项目的各种属性;需要列式数据库,如HBase、Cassandra等;
- 倒排:一般以特征为key,得到一系列项目等;需要KV数据库,如Redis等;
- 分布式参数服务器:存储机器学习模型参数;
- ElasticSearch:
常见开源工具/轮子
内容分析
| 场景 | 接口语言 | 分布式 | 支持方 | |
|---|---|---|---|---|
| LightLDA | 主题模型 | C++ | 分布式 | Microsoft |
| gensim | 主题模型,词嵌入 | Python | 单机多线程 | adimrehurek.com |
| plda | 主题模型 | C++ | 单机多线程、分布式 | |
| DMWE | 词嵌入 | C++ | 分布式 | Microsoft |
| tensorflow-word2vec | 词嵌入 | Python | 分布式、单机 | |
| FastTest | 词嵌入,文本分类 | C++、Python | 单机多线程 | |
| liblinear | 文本分类 | C++、Python、Java等 | 单机 | 台湾大学 |
协同过滤
| 场景 | 接口语言 | 分布式 | 支持方 | |
|---|---|---|---|---|
| kgraph | knn相似度计算和搜索 | C++、Python | 单机多线程 | aaalgo |
| annoy | 稠密低维向量KNN相似搜索 | C++、Python | 单机多线程 | spotify |
| faiss | 稠密低维向量KNN相似搜索,聚类 | C++、Python | 单机多线程、GPU加速 | |
| nmslib | 稠密低维向量KNN相似搜索 | C++、Python | 单机 | nmslib |
| spark.rowmatrix.columnsimilarities | 基于用户/物品的协同过滤 | Scala、Java、Python | 单机多线程 | |
| lightfm | SVD矩阵分解,SVD++矩阵分解,BPR矩阵分解 | Python | 单机多线程 | lyst |
| implicit | 基于用户/物品的协同过滤,ALS矩阵分解,BPR矩阵分解 | Python | 单机多线程、GPU加速 | benfrederickson.com |
| QMF | 加权ALS矩阵分解,BPR矩阵分解 | C++、Python | 单机多线程 | Quora |
搜索、推荐、广告
| 搜索 | 推荐 | 广告 | |
|---|---|---|---|
| 信息连接方式 | 拉 | 推、拉 | 推 |
| 关注点 | 消费者 | 消费者、生产者 | 生产者 |
| 是否需要惊喜 | 否 | 是 | 可以 |
| 倒排索引 | 用 | 一般用 | |
| 目标 | 精准、权威、质量 | 多样性、吸引力、整体效果 | 精确 |
| 训练 | point-wise,pair-wise,list-wise | point-wise | |
| 模型偏好 | 双塔 | 序列 | 注意力 |
| 辅助策略 | 对搜索词和内容的理解 | 多样性、长期兴趣 | 价格、成本、利润 |
- 共同架构:过滤/召回、排序
经典推荐算法
基于流行度/热度/热门/排行榜
特点
- 非个性化;
- 降级的推荐系统,在没有其它信息及其它策略出问题的时候兜底,可以类比一个信号的均值分量;
- 可以作为老用户的兴趣发现方式
排序策略
- 绝对热度、比例(绝对热度/展示量,抵消展示量的偏差),缺点:
- 容易被攻击/刷榜;
- 马太效应,一些项目长期存在;
- 考虑时间因素:让排序因素随时间衰减;
- 考虑多种行为:如用户除了点击等赞成行为,还可能有踩等反对行为,以及一些可以反映项目质量的指标;
- 考虑置信区间/威尔逊分数:根据样本数,计算好评率的置信分数,样本不足时,置信区间很宽;
- 先验流行度:当项目没有曝光或曝光量较小时,无法计算绝对热度和比例,可以通过加入先验信息来得到一个流行度。
- 贝叶斯估计:根据全局或所属类别特征,得到先验的曝光量和点击量,在此基础上进行累加,得到平滑的流行度。
- 时间段转化:如果流行度是针对一段时间的,可以将上一段时间的曝光量和点击量乘以一个时间折扣系数作为这一时间段的先验。
协同过滤
经典协同过滤(CF)
- 协同+过滤:相似+信息共用+过滤信息
- 缓解单个用户/项目信息不足
基于相似用户的协同过滤
- 计算相似用户+用相似用户对于物品的评分组合得到目标用户对于物品的评分
- 组合方式
- 平均
- 按相似用户相似度加权平均
- 减去相似用户的打分偏置后加权平均
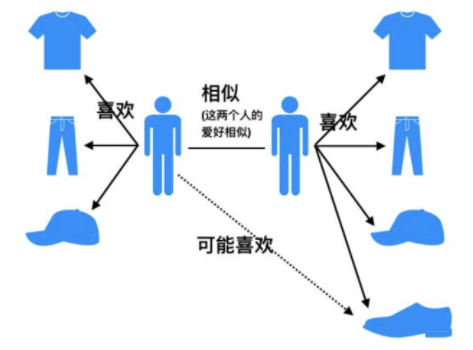
缺点:
- 数据稀疏:用户只会购买极少数商品
- 计算量大
基于相似物品的协同过滤
- 物品与用户有着对等的关系,因此也可以从物品的角度进行协同过滤
- 找到用户的偏好物品+计算物品的相似物品
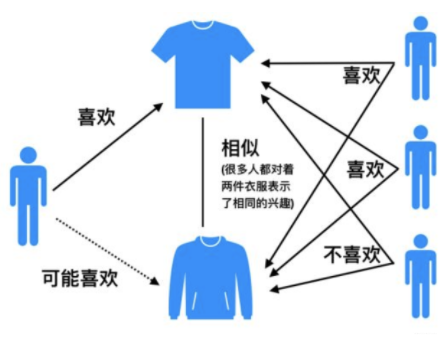
缺点:
热门物品跟很多物品都相似
一般用户少的时候更适合基于用户的协同过滤;物品少的时候更适合基于物品的协同过滤。
swing
- 基于物品的相似使用购买物品的用户来代表物品,但用户很多,这具有很多噪声,泛化性不够
- swing从用户共同购买的角度的获得物品的相似性
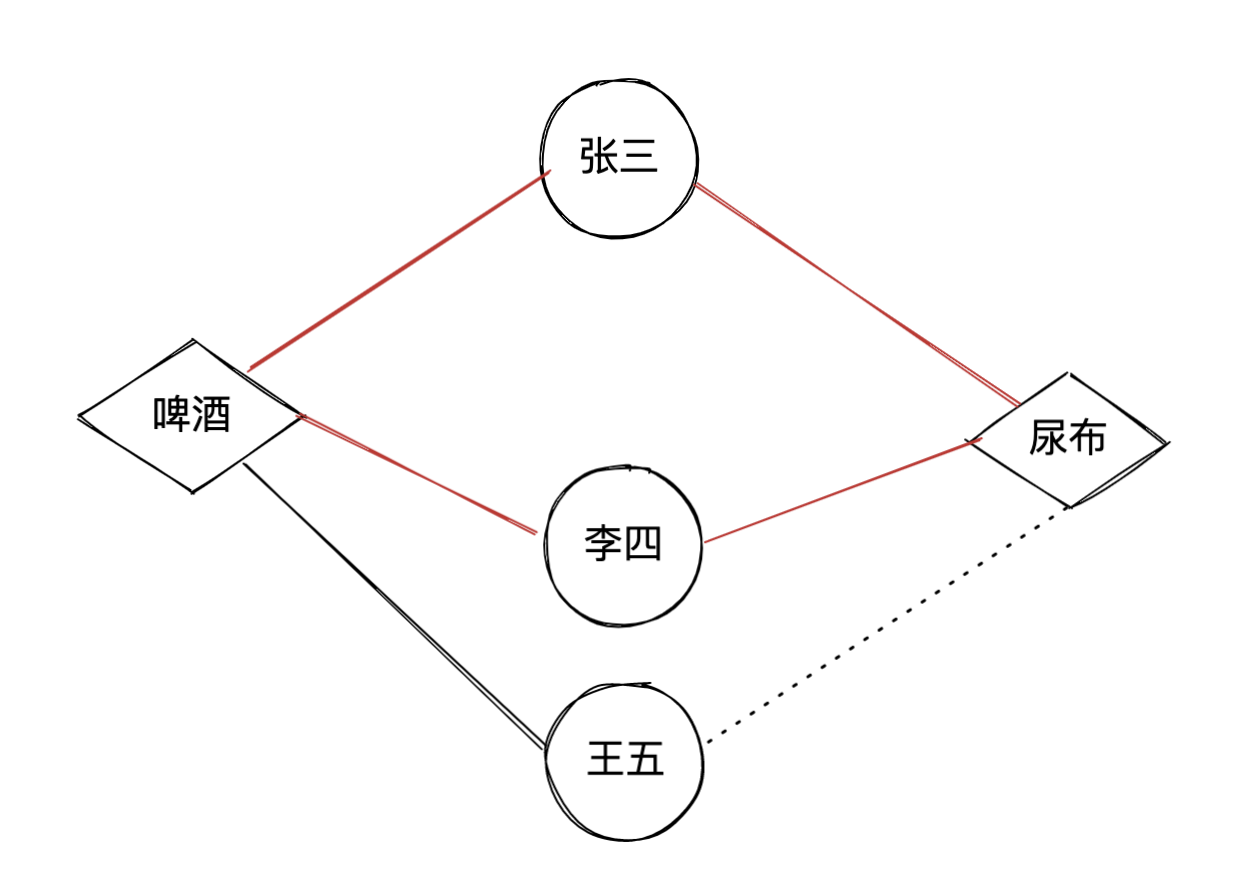 计算公式:
$$s(i,j)=\sum\limits_{u\in U_i\cap U_j} \sum\limits_{v \in U_i\cap U_j}w_uw_v \frac{1}{\alpha+|I_u \cap I_v|}$$
其中$U_i$ 是点击过商品i的用户集合,$I_u$ 是用户u点击过的商品集合,$\alpha$是平滑系数。
计算公式:
$$s(i,j)=\sum\limits_{u\in U_i\cap U_j} \sum\limits_{v \in U_i\cap U_j}w_uw_v \frac{1}{\alpha+|I_u \cap I_v|}$$
其中$U_i$ 是点击过商品i的用户集合,$I_u$ 是用户u点击过的商品集合,$\alpha$是平滑系数。
$w_u=\frac{1}{\sqrt{|I_u|}},w_v=\frac{1}{\sqrt{|I_v|}}$是用户权重参数,来降低活跃用户的影响。
缺点:计算复杂度高
Item2Vec
- 基于Word2Vec的Skip-Gram模型计算物品的相似度,并且还丢弃了时间、空间信息。
- 也可以考虑上时间
- 基于Item2Vec得到物品的向量表示后,物品之间的相似度可由二者之间的余弦相似度计算得到。
- 可以看出,Item2Vec在计算物品之间相似度时,仍然依赖于不同物品之间的共现。因为,其无法解决物品的冷启动问题。
- 一种解决方法:取出与冷启物品类别相同的非冷启物品,将它们向量的均值作为冷启动物品的向量表示。
基于矩阵分解(MF)
- 矩阵分解的流行起源于10年前的Netflix大赛,当时各类矩阵分解模型都在实际数据中起到了很好的效果。
隐变量
- “隐藏的变量”或者叫“隐藏的参数”
- 如混合高斯分布中,一个样本可能来自不同的高斯分布,在每一个高斯分布上有一个权重;样本在各个分布上的权重就是隐变量。
矩阵分解
- 将$m * n$的用户项目交互矩阵分解为$m * k$和$k * n$的两个低秩矩阵的乘积;
- 每一个长度为$k$的低维向量用来代表一个用户或项目,其中有$k$个隐变量;
- 每一个隐变量指示一个隐含的分布/特征,虽然不能直接说出这些隐变量的含义,但是可以通过隐变量预测用户和项目的可能交互概率。
- 通过矩阵分解可以极大地降低参数量,提升参数的泛化性能;
分解方式
- 交替最小二乘法:两个潜在矩阵交替寻优;
- 梯度下降;
- 其它各种数学方法,SVD分解,概率矩阵分解。。。
提取偏置信息
- 不同的人、项目、全局的平均分都不一样,可以将这个平均分/偏置提取出来单独学习
加入特征信息
- 经典的矩阵分解有冷启动的问题;没有利用各种其它特征信息。
- 加入特征信息的方式是将隐向量写成各种特征信息的组合,这样在学习的过程中不仅可以学到隐向量,还可以得到各个特征的表示,解决冷启动,还可以对隐向量表示起到一定的正则化效果。
划分时间
- 不同时间的数据训练不同的隐向量
张量分解(TF)
- 张量分解是矩阵分解的推广,矩阵分解运用在用户和项目两个角度,而张量可以拓展到更高的角度,如用户、项目、上下文。
- 张量分解的方法:
- CP分解:把$mnr$的用户项目上下文矩阵分解为$m * k$和$n * k$和$r * k$低秩矩阵,小矩阵可以相乘直接还原出原矩阵;
- 高阶奇异值分解:把$m * n * r$的用户项目上下文矩阵分解为$m * a$和$n * b$和$r * c$低秩矩阵,小矩阵不能直接还原出原矩阵,但是自由度更高;
- 张量分解的稀疏性问题更加严重
- 矩阵分解和张量分解都可以用神经网络代替后面的内积运算/还原过程,得到能力更强的现代推荐算法。
协同矩阵分解(CMF)
当有多种交互信息,如用户项目交互矩阵、用户用户关系矩阵时,矩阵分解无法同时利用两个矩阵的信息;协同矩阵分解的思路是让两个矩阵分解进行参数共享,来使得最终学到的低秩矩阵包含两种信息。
神经协同过滤(NCF)
- 可以看成矩阵分解的非线性拓展,将用户侧embedding与项目侧embedding共同通过神经网络得到输出;
- 可以通过加入side info来使用特征信息,缓解冷启动;
基于内容&特征交叉
基于内容信息/LR
- 把推荐系统当做监督学习任务来看待,输入用户和物品各种特征,预测点击量、购买率等信息。
- 核心就是认为需要预测的变量(评分、点击率等等)是所有显式变量的一个回归结果。
- 最基础的模型是逻辑斯蒂回归(LR):学习各个特征权重,不能直接学到交叉特征;如果要交叉特征需要手动交叉,泛化性差;
分解机(FM)
- 基于内容+矩阵分解思想
- 主体是基于内容的做法,输入特征,得到预测值
- 在LR的基础上增加二阶交叉特征,用矩阵分解的方式得到交叉特征的权重,降低参数量,提升泛化性
- FM模型的公式定义如下:
$$ \hat{y}(\mathbf{x}):=w_{0}+\sum_{i=1}^{n} w_{i} x_{i}+\sum_{i=1}^{n} \sum_{j=i+1}^{n}\left\langle\mathbf{v}{i}, \mathbf{v}{j}\right\rangle x_{i} x_{j} $$
- 其中,$i$ 表示特征的序号,$n$ 表示特征的数量;$x_i \in \mathbb{R}$ 表示第 $i$ 个特征的值。
- $v_i,v_j \in \mathbb{R}^{k} $ 分别表示特征 $x_i,x_j$ 对应的隐语义向量(Embedding向量),$\left\langle\mathbf{v}{i}, \mathbf{v}{j}\right\rangle :=\sum_{f=1}^{k} v_{i, f} \cdot v_{j, f}$
- $w_0,w_i\in \mathbb{R}$ 均表示需要学习的参数。
观察FM的二阶特征交互项,可知其计算复杂度为 $O\left(k n^{2}\right)$ 。为了降低计算复杂度,按照如下公式进行变换。
$$\sum_{i=1}^{n} \sum_{j=i+1}^{n} \left\langle\mathbf{v}{i}, \mathbf{v}{j}\right\rangle x_{i} x_{j} \\
= \frac{1}{2} \sum_{i=1}^{n} \sum_{j=1}^{n}\left\langle\mathbf{v}{i}, \mathbf{v}{j}\right\rangle x_{i} x_{j}-\frac{1}{2} \sum_{i=1}^{n}\left\langle\mathbf{v}{i}, \mathbf{v}{i}\right\rangle x_{i} x_{i} \\
= \frac{1}{2}\left(\sum_{i=1}^{n} \sum_{j=1}^{n} \sum_{f=1}^{k} v_{i, f} v_{j, f} x_{i} x_{j}-\sum_{i=1}^{n} \sum_{f=1}^{k} v_{i, f} v_{i, f} x_{i} x_{i}\right) \\
= \frac{1}{2} \sum_{f=1}^{k}\left(\left(\sum_{i=1}^{n} v_{i, f} x_{i}\right)^{}\left(\sum_{j=1}^{n} v_{j, f} x_{j}\right)-\sum_{i=1}^{n} v_{i, f}^{2} x_{i}^{2}\right) \\
= \frac{1}{2} \sum_{f=1}^{k}\left(\left(\sum_{i=1}^{n} v_{i, f} x_{i}\right)^{2}-\sum_{i=1}^{n} v_{i, f}^{2} x_{i}^{2}\right)
$$
- 公式变换后,计算复杂度由 $O\left(k n^{2}\right)$ 降到 $O\left(k n\right)$。
基于域的分解机(FFM)
- Field-aware Factorization,在FM的基础上引入Field的概念,每一个特征不止有一个隐因子向量,而是对不同的Field各有一个隐因子向量;
- FM在LR的基础上大幅降低参数量,提升泛化性,而FFM则是在FM的基础上后退一步,增加参数量,提升模型表达能力;
PNN
设计Product层先对低阶特征进行充分的交叉组合之后再送入到DNN中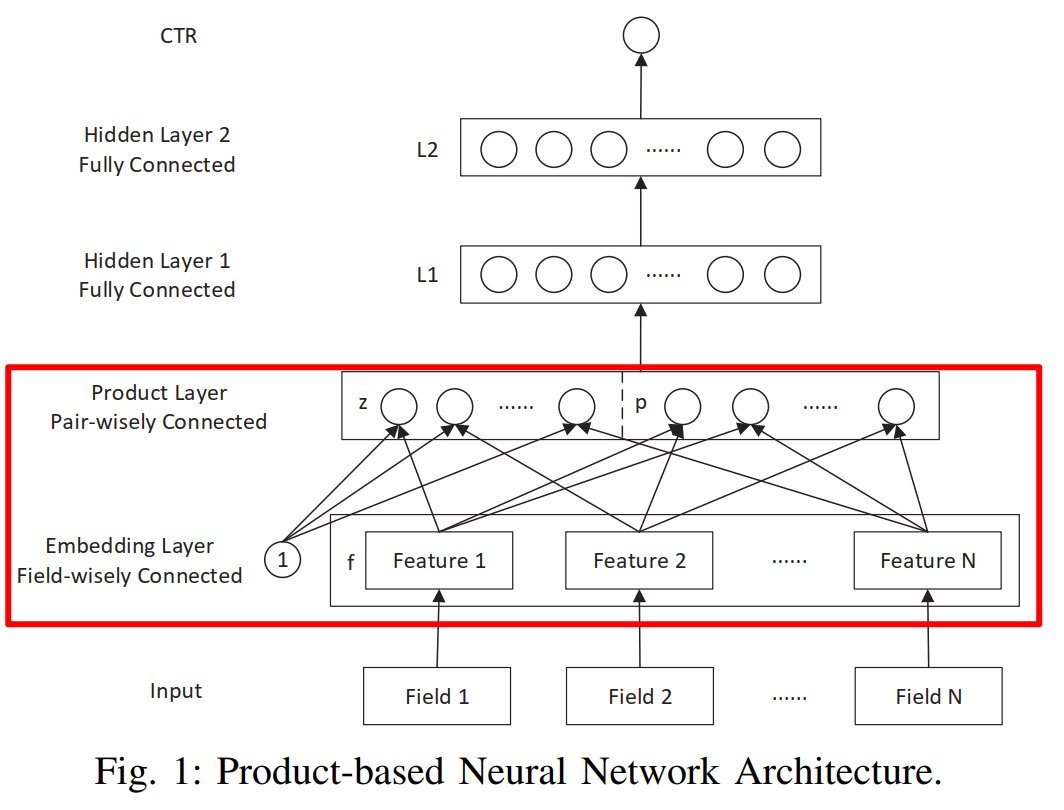
Product层有线性和非线性两部分。
其中线性部分是将输入特征直接做线性变换:
$$l_z^n = W_z^n \odot{z} = \sum_{i=1}^N \sum_{j=1}^M W^n_{z,i,j} z_{i,j}$$
非线性部分则是先对输入embedding先做交叉再做线性变换:
$$ \begin{aligned} l_p^n &= W_p^n \odot{p} \\ &= \sum_{i=1}^N \sum_{j=1}^N W^n_{p,i,j}p_{i,j} \\ &= \sum_{i=1}^N \sum_{j=1}^N W^n_{p,i,j} f_i f_j^T \end{aligned} $$
LR+GBDT
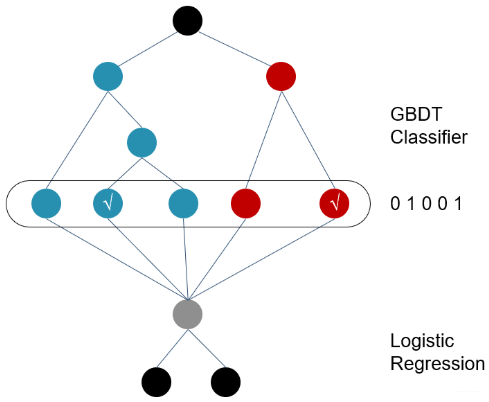
- GBDT适合做特征组合,每一棵树就是在依次组合出不同的交叉特征;LR为每一棵树的结果学习权重;
- 通过树模型得到高阶交叉特征;
- 通过GBDT进行特征组合之后得到的离散向量是和训练数据的原特征一块作为逻辑回归的输入, 而不仅仅全是这种离散特征
- 建树的时候用ensemble建树的原因就是一棵树的表达能力很弱,不足以表达多个有区分性的特征组合,多棵树的表达能力更强一些。GBDT每棵树都在学习前面棵树尚存的不足,迭代多少次就会生成多少棵树。
- RF也是多棵树,但从效果上有实践证明不如GBDT。且GBDT前面的树,特征分裂主要体现对多数样本有区分度的特征;后面的树,主要体现的是经过前N颗树,残差仍然较大的少数样本。优先选用在整体上有区分度的特征,再选用针对少数样本有区分度的特征,思路更加合理,这应该也是用GBDT的原因。
- 在CRT预估中, GBDT一般会建立两类树(非ID特征建一类, ID类特征建一类), AD,ID类特征在CTR预估中是非常重要的特征,直接将AD,ID作为feature进行建树不可行,故考虑为每个AD,ID建GBDT树。
- 非ID类树:不以细粒度的ID建树,此类树作为base,即便曝光少的广告、广告主,仍可以通过此类树得到有区分性的特征、特征组合
- ID类树:以细粒度 的ID建一类树,用于发现曝光充分的ID对应有区分性的特征、特征组合
Wide&Deep
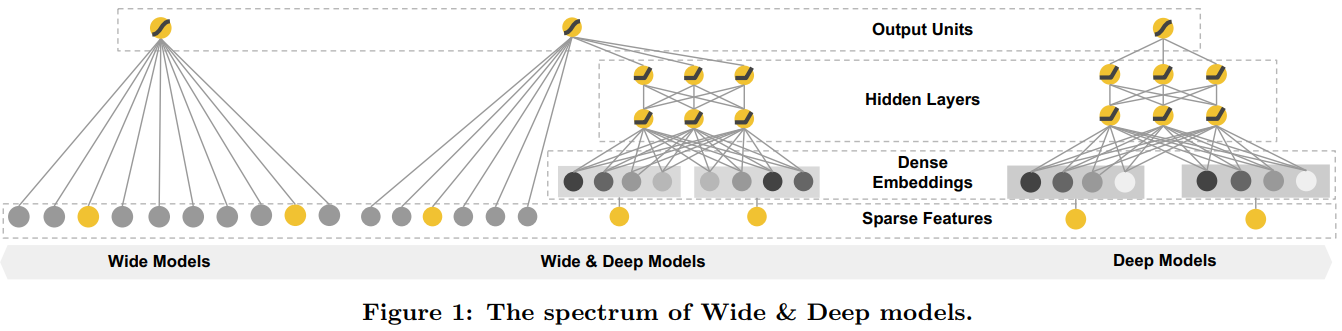
- Wide部分就是LR,擅长记忆,可以拿到用户的基本偏好;Deep部分擅长学习泛化能力的特征。
- Wide部分使用带L1正则化的
Follow-the-regularized-leader(FTRL)进行优化,以提升稀疏性,去掉不重要的特征;Deep采用正常的AdaGrad进行优化。
$$
\phi_{k}(x)=\prod_{i=1}^d x_i^{c_{ki}}, c_{ki}\in {0,1} \\
a^{(l+1)} = f(W^{l}a^{(l)} + b^{l}) \\
P(Y=1|x)=\delta(w_{wide}^T[x,\phi(x)] + w_{deep}^T a^{(lf)} + b)
$$
DeepFM
- 类似于Wide&Deep,一边用FM,另一边用神经网络得到高阶交叉特征;
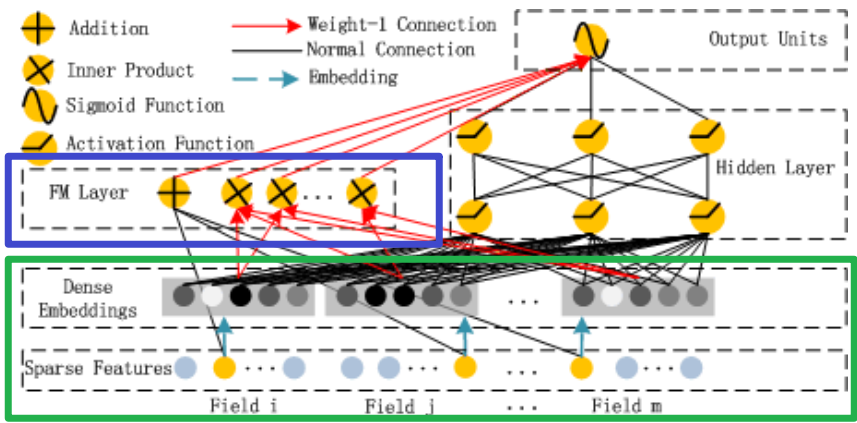
DCN
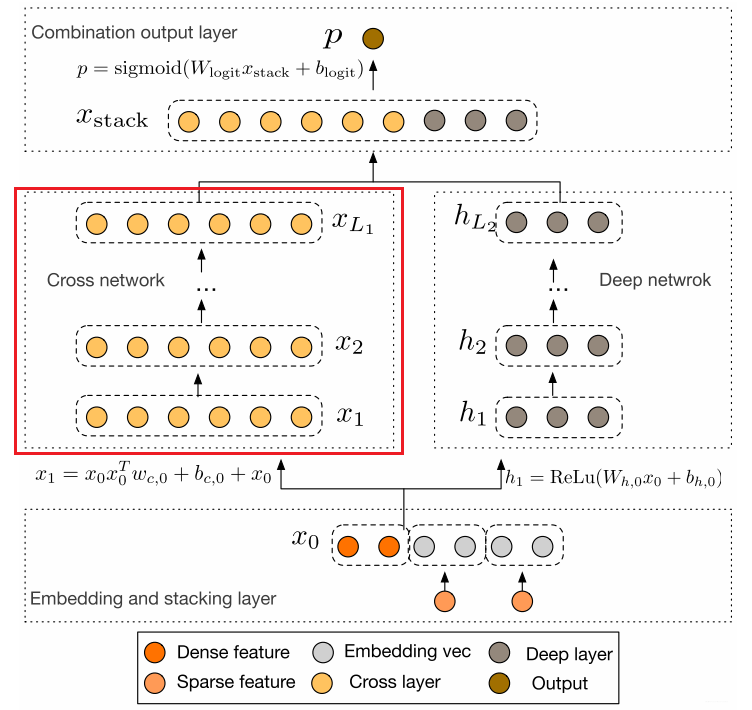
- 离散特征转化为embedding,与dense特征级联,得到输入向量;
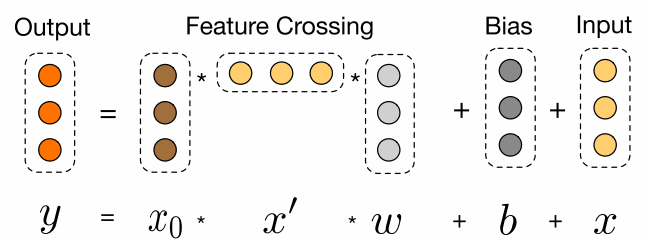
- cross网络和deep网络并联,即用cross网络代替Wide&Deep模型中的Wide部分:
- cross网络的公式:$x_{l+1}=x_0x^T_lw_l+b_l+x_l$,其中$x_0x^T_lw_l$将上一层的embedding与输入交叉,最后的$x_l$则以直连的方式实现残差连接;
- deep网络则通过MLP使用特征组合的方式;
AutoInt
Wide&Deep家族的Wide不能得到很深的交叉特征,Deep的交叉不具有可解释性
AutoInt采用transformer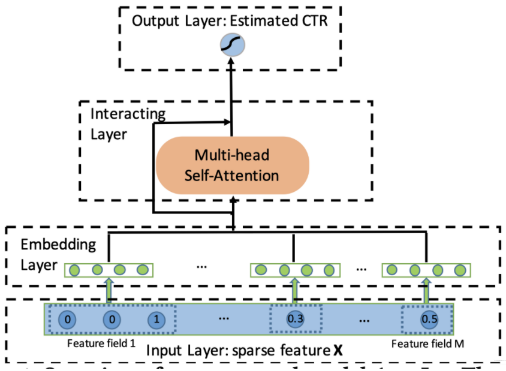
用户历史行为
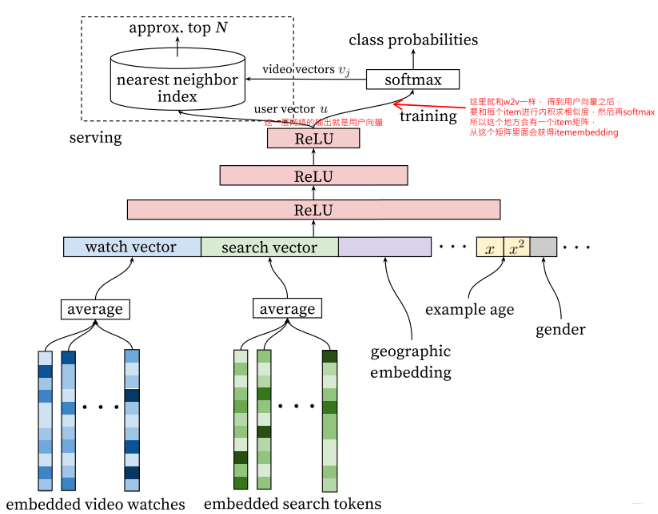
YoutubeNet
- 将用户历史观看的视频embedding通过mean pooling来得到一个用户侧特征;然后用户侧特征级联得到一个向量,通过MLP得到用户embedding;
Spotify
- 用循环神经网络来做歌单的下一首歌推荐;
DIN/Deep Interest Network
- 将用户交互历史序列作为特征信息输入;
- 对用户交互序列进行attention加权pooling,重点关注与此次打分相关的历史项目,可以起到多兴趣的效果;
- attention是计算历史交互项目与待打分项目之间的关系;
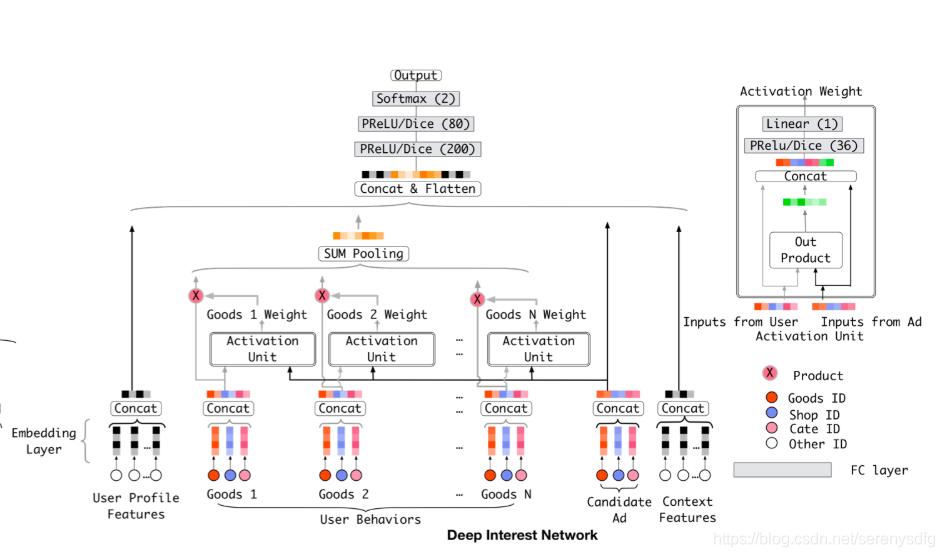
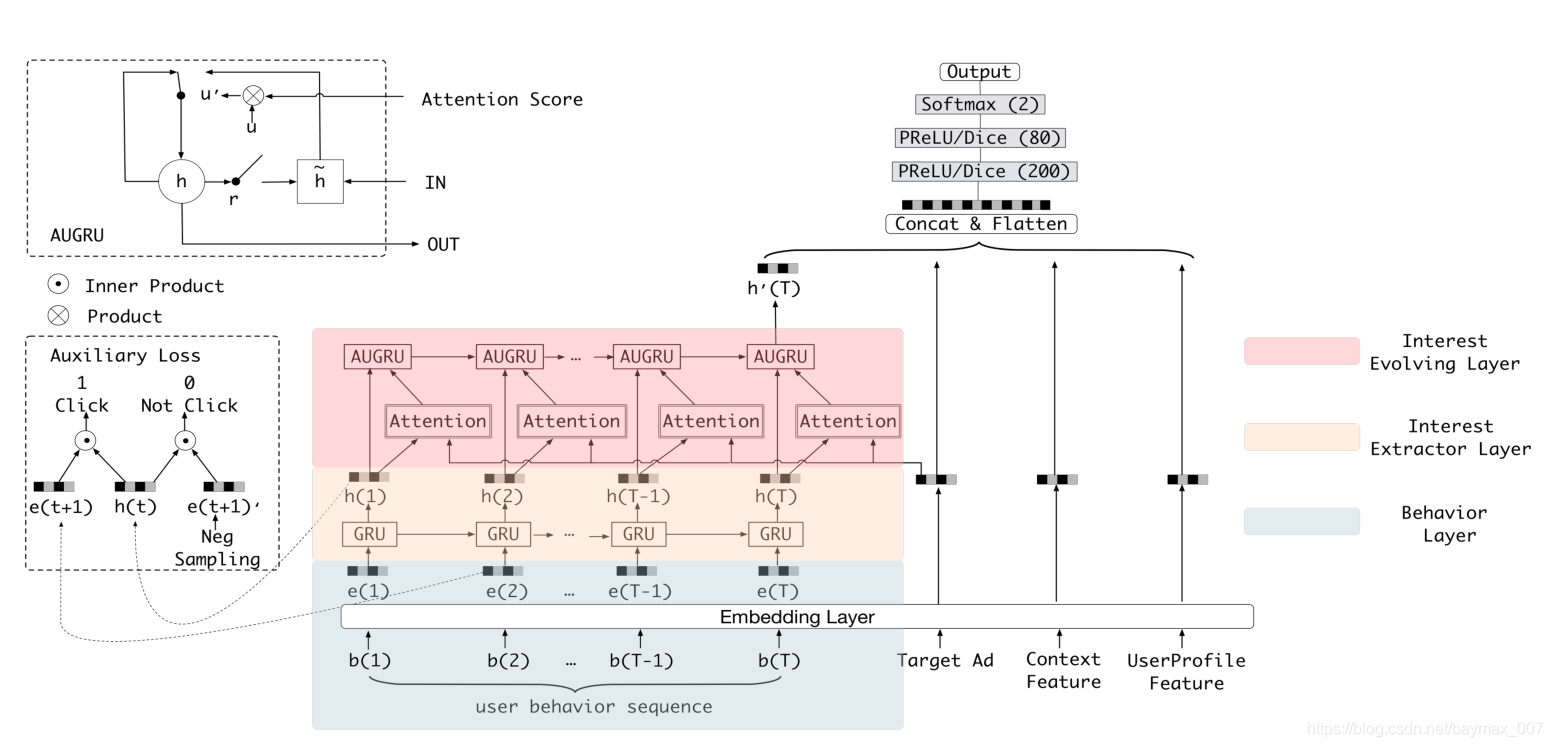
DIEN/Deep Interest Evolution Network
- DIN等直接将用户历史看做用户兴趣,难以反应用户潜在兴趣和用户兴趣演变;
- Interest Extractor层用GRU对用户交互行为进行基础的兴趣建模;并引入辅助loss,将序列中的下一个item用来监督上一个单元的输出,降低GRU层的长时间依赖问题,降低优化难度;
- Interest Evolving层用带注意力更新门的GRU/AUGRU来学习兴趣演化过程,每个项目与待打分项目计算权重,用于更新隐状态;
- 在用户行为序列的信息利用上,结合了注意力和GRU的优势,能更好的表达兴趣和兴趣演化;
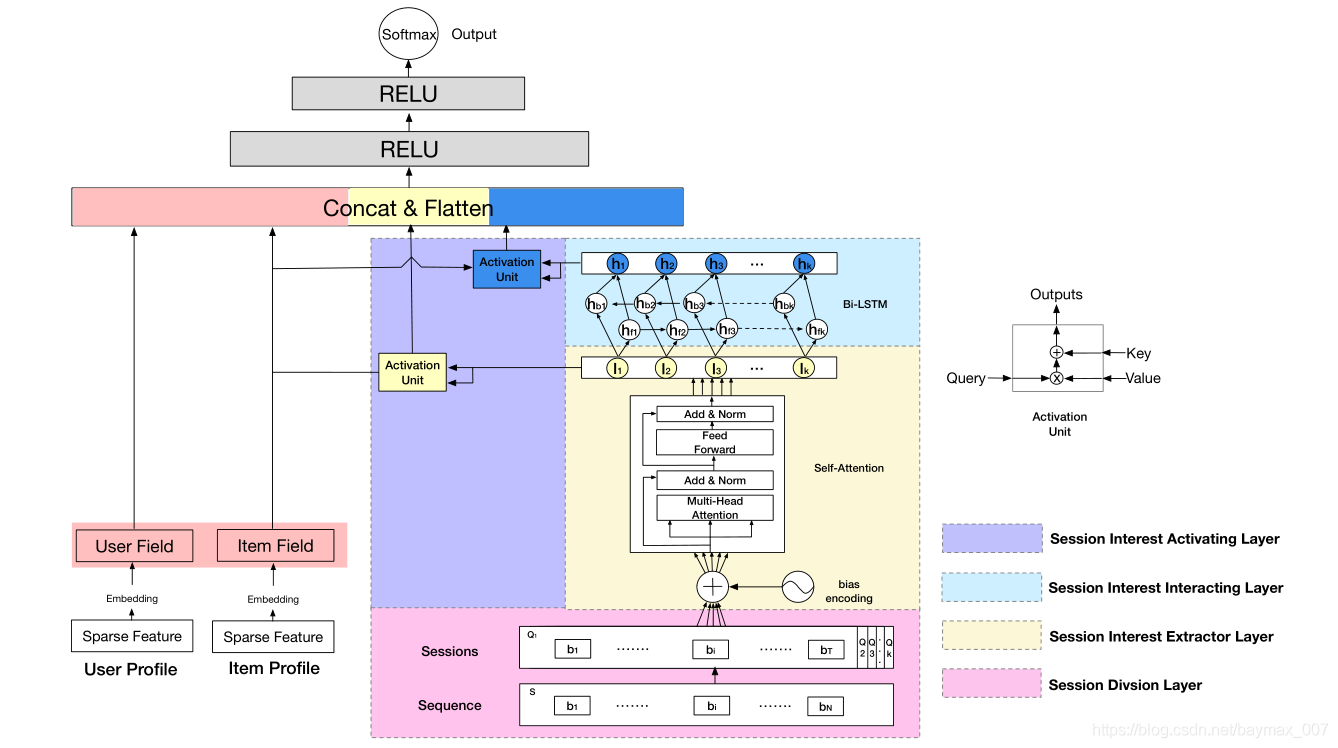
DSIN/Deep Session Interest Network
- 引入session的信息,根据sequence中项目的时间间隔进行切分,超过30min就认为是两个session,同一个session中的历史交互项目高度同构,而不同session高度异构;
- 使用带有bias编码的自注意力模块来抽取用户每个session的兴趣特征,表示编码起到位置编码的作用;
- 使用Bi-LSTM去捕捉用户在多个历史会话中兴趣的交互和演变;
- 计算待打分项目与各个session的相似度,加权求和;
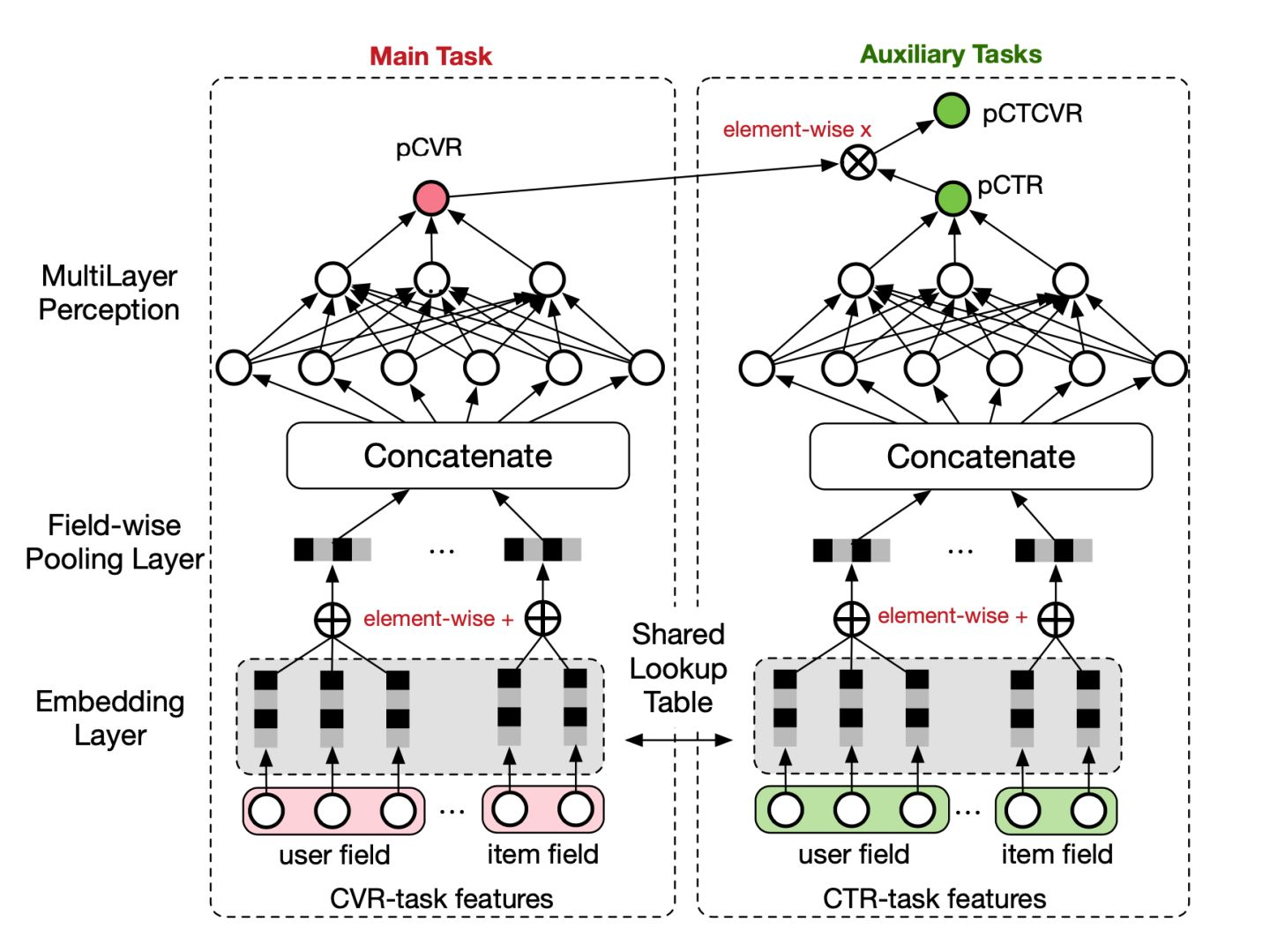
多目标
ESMM/Entire Space Multi-Task Model
- 两个完全一样的子模型学习pCTR和pCVR,然后将这两个值相乘得到pCTCVR,损失函数是pCTR和pCTCVR的乘积;
- pCTR的正样本是有点击行为的曝光事件,负样本是没有点击行为的曝光事件。PCTCVR的正样本是同时具有点击和转化的曝光事件,负样本是没有点击的或者点击没有转化的曝光事件。
- 两个子模型共享embedding,缓解数据稀疏性的问题;
- 结构设计使得pCVR的子模型也可以从曝光未点击的样本中学习;缓解使用用户点击的样本来训练,而用的整个样本空间来预测的样本选择偏差;
MMoE/Multi-gate Mixture-of-Experts
- 许多多目标的模型采用Shared-Bottom的方式,共享底层网络,在多目标任务接近时效果较好,而在多目标差异较大时效果一般;
- MoE是使用简单的前馈神经网络和可训练门控单元组成的子结构,门控单元根据输入控制前馈神经网络的输出;
- MMoE用多个MoE并行代替Shared-Bottom网络,当多任务的相关性越低时,MMoE的效果越明显;
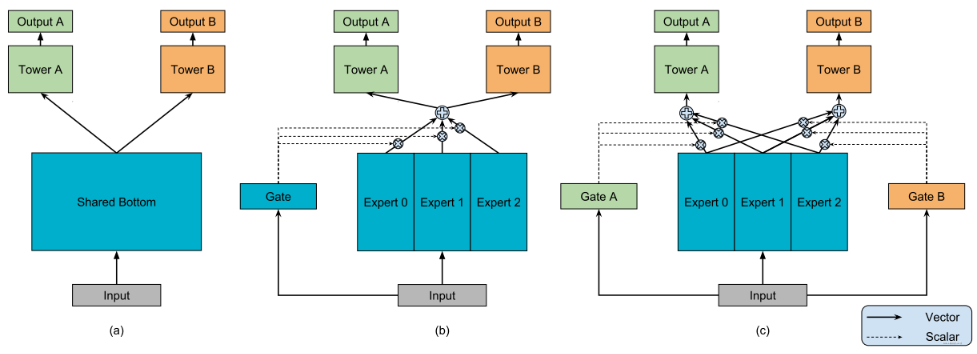
PLE
- 任务学习中不可避免的两个缺点:
- 负迁移(Negative Transfer):针对相关性较差的任务,使用shared-bottom这种硬参数共享的机制会出现负迁移现象,不同任务之间存在冲突时,会导致模型无法有效进行参数的学习,不如对多个任务单独训练。
- 跷跷板现象(Seesaw Phenomenon):针对相关性较为复杂的场景,通常不可避免出现跷跷板现象。多任务学习模式下,往往能够提升一部分任务的效果,但同时需要牺牲其他任务的效果。即使通过MMOE这种方式减轻负迁移现象,跷跷板问题仍然广泛存在。
CGC(Customized Gate Control) 定制门控在结构上设计的分化,实现了专家功能的分化;
而PLE则是通过分层叠加,使得不同专家的信息进行融合。
整个结构的设计,是为了让多任务学习模型,不仅可以学习到各自任务独有的表征,还能学习不同任务共享的表征。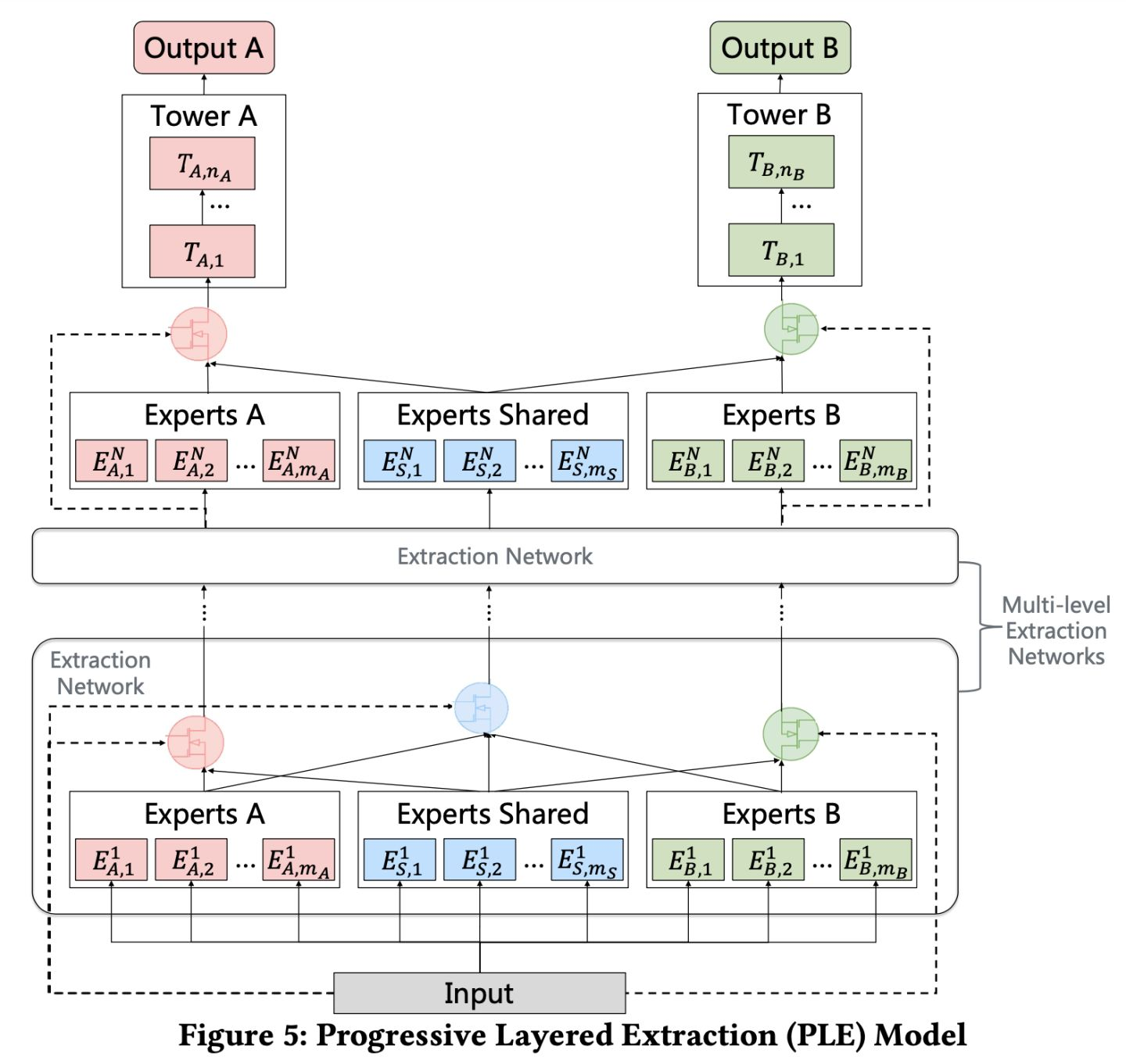
不同多任务模型抽象: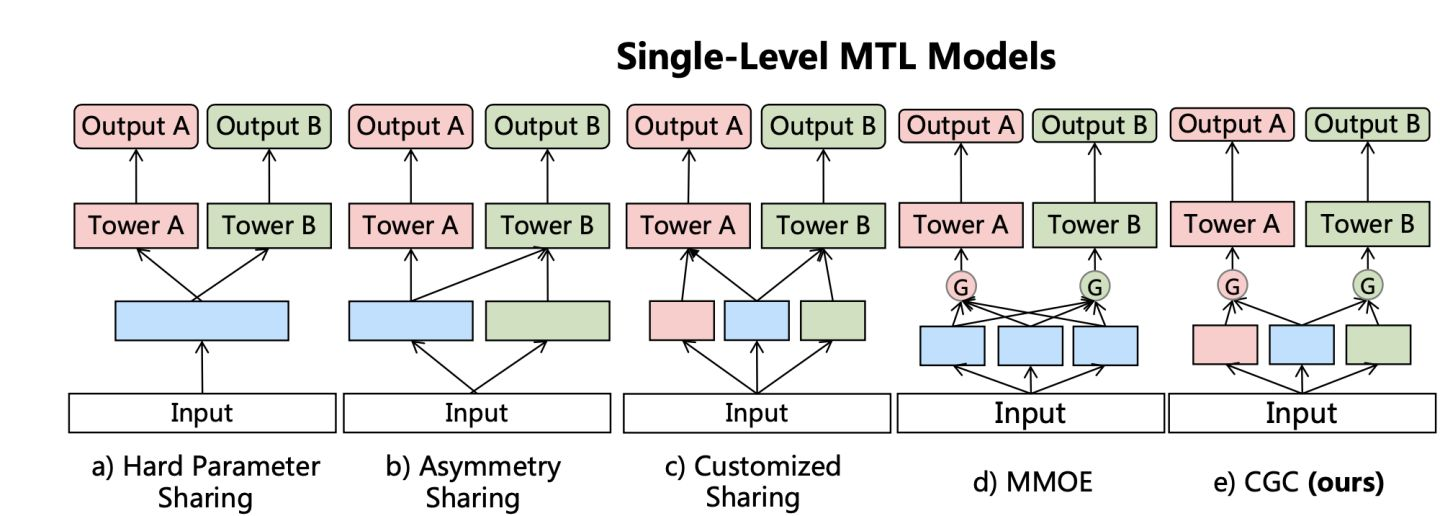
多兴趣
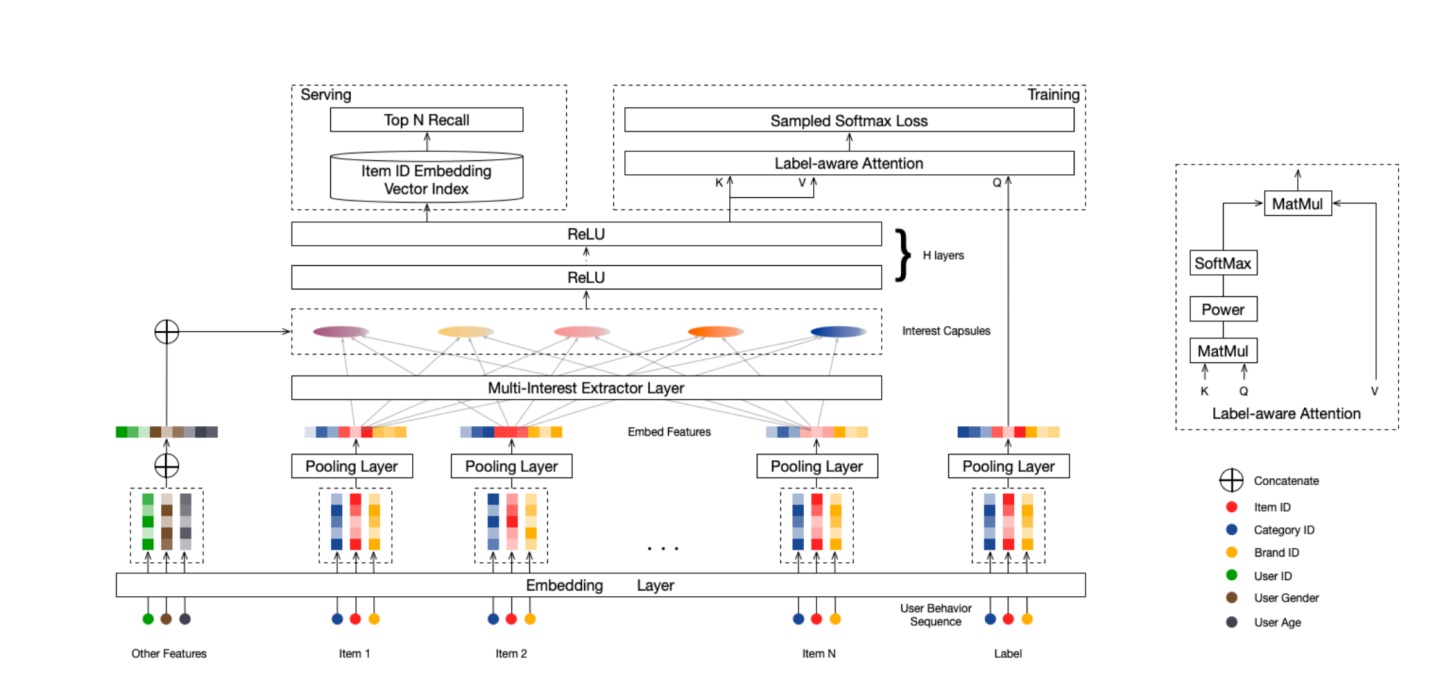
MIND/Multi-Interest Network with Dynamic Routing for Recommendation at Tmall
- 一般的召回是根据用户属性及历史交互项目为用户生成一个表示向量,同时用项目属性给项目生成一个表示向量,计算其相似度;多兴趣网络的不同是会为用户生成多个不同的交互向量,以表征用户在多方面的兴趣;
- Embedding && Pooling:用户侧特征embedding做concat,项目侧特征embedding做average pooling;
- 根据$K_u=max(1,min(K,log_2(|I_u|)))$自适应地计算一个用户的兴趣数量,其中$|I_u|$表示用户的历史交互数量;
- 胶囊网络的兴趣提取在每一个兴趣胶囊和每一个历史交互项目之间计算,因为兴趣和历史项目之间的路由系数是随机初始化的,所以每个兴趣胶囊会以不同比例提取历史交互项目的信息;
- 每个兴趣表示都与用户属性embedding级联通过MLP得到用户表示;
- 训练阶段目标项目与用户表示通过计算注意力得到最终的相似度;而召回时采用每一个用户表示分别召回;
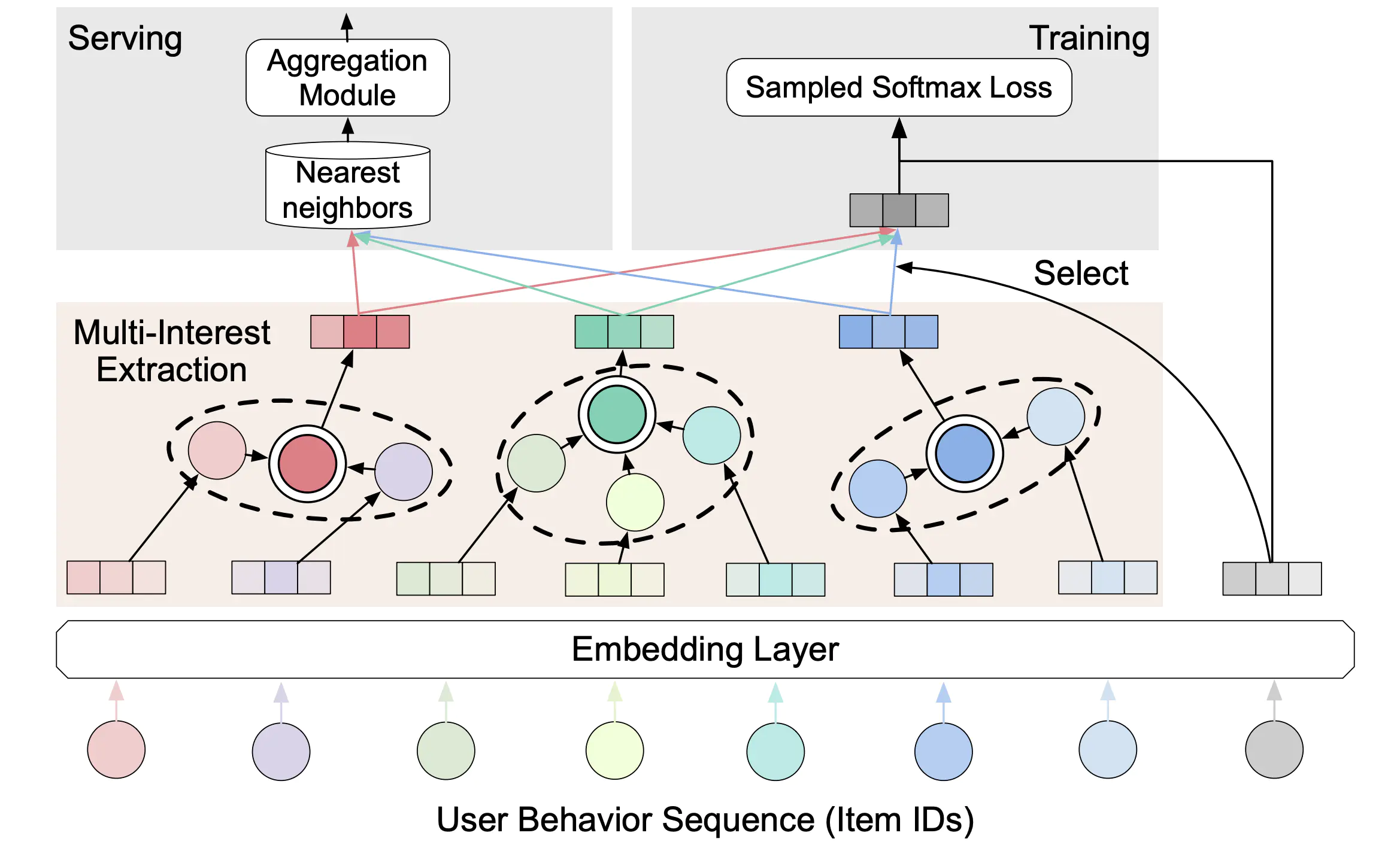
ComiRec/Controllable Multi-Interest Framework for Recommendation
- 相比MIND只使用用户交互序列来作为用户侧输入;
- 因为兴趣固定,所以胶囊网络可以使用原始版本;
- 还提出了使用Self-Attentive的方式来捕捉多兴趣;
- 训练阶段直接选择最接近的兴趣表示,不进行组合,网络更浅;
- 在线上召回时还考虑召回项目之间的多样性;
常见策略
多目标
目的&困难
- 推荐系统中的数据大多是隐式反馈;
- 且以漏斗的形式出现,如电商场景下的点击、收藏、加购物车、购买、评价等,数量依次减少;
- 同时有许多可以共同优化的目标,如留存、观看时长、分享等;
- 众多的目标都是我们想要优化的:优化多目标可以得到更多的数据量,缓解数据稀疏性;
- 优化多目标有许多困难:
- 不同用户的表达偏好不同,有的倾向于点赞,有的倾向于收藏等;
- 不同物品的目标之间存在偏差,如标题党在点击量上占优势;
- 不同目标的重要程度不一样,如购买高于收藏;
改变样本权重
- 对重要的优化目标的样本给更大的权重,可以在不调整模型架构的情况下,实现多个目标的预测;
- 没有对多目标进行建模,样本权重的确定比较主观;
多模型分数融合
- 排序阶段为每一个目标单独训练出一个分数,然后在重排阶段将这些分数组合成一个新的分数,可以采用连乘、指数等方式;
- 模型简单,但是分数融合的超参数难以学习;
排序学习(Learning To Rank,LTR)
- 借助pair-wise的训练方式,让重要的目标排在前面,如购买比点击重要,则购买的商品应该排在点击的商品前面;
- 只需要单个模型,不需要设计主观的超参数;
- 样本不平衡的问题可能会被放大,如点击10次在这里也还是算一次;
多任务学习(Multi-Task Learning,MTL)
- 思想类似于迁移学习;
基于参数的共享/Parameter Based
- 多个任务共用底层的网络结构,在后面分开采用不同的结构;
- 如果多个目标直接的关联性强,则可以起到相互增强的想过,缓解数据稀疏;反之如果关联性不强则可能相互干扰;
基于约束的共享/Regularization Based
- 每个任务有各自的模型和参数,可以选择对不同模型的一些参数加上约束,如通过L2正则化来拉近它们的距离;
去重
内容源去重
- 对不同来源的内容进行重复识别和过滤;
曝光过滤/去重
- 过滤类型:
- 历史曝光
- 历史曝光类似
- 同一产品不同位置重复
- 过滤位置:
- 召回:
- 如果使用es框架,可以在召回前做,将用户曝光序列或曝光相似序列作为not query;
- 如果使用redis等kv存储结构,不支持查询时,过滤时则在召回后过滤。
- 重排:在计算资源足够的情况下,可以在重排阶段,对相似度高的项目进行过滤
- 召回:
重复识别
- hash算法:如MD5,缺点是内容改一点点,指纹/哈希值就会非常不同,无法识别类似或者说几乎一致的内容;
- Simhash:所产生的hash签名在一定程度上可以表征原内容的相似度。
- 流程:分词并设计权重、词hash成整数/二进制序列、加权合并、得到Simhash签名、计算汉明距离
- 寻找重复的优化:两两计算记录复杂度高,可以通过哈希表的思路简化;
- Bloomfilter/布隆过滤器:通过多个独立的hash函数共同判断是否重复;
加权采样
应用场景
- 标签召回时,标签数量多,如果全用计算量大,用一部分则会丢失信息,通过加权采样可以:
- 大大减少召回时的计算复杂度;
- 可以保留更多的用户标签/信息;
- 每次召回计算时还能有所变化;
- 虽然有变化,但是依然受标签的权重相对大小约束。
- 排行榜的分数由许多元素组成,可以进行采样
有限数据集采样
- 生成随机数,乘以权重,排序取top,得到的结果与权重成正比;
- 在指数分布上采样,将权重融入到分布参数中;
无限数据集
- 蓄水池采样:需要$k$个样本,当第$n$个样本到来时,以$\frac{k}{n}$的概率替换原有缓存,以保证流式数据可以等概率采样;
召回
- 一般是多路召回,每一路从一个角度出发,获取一个方面的待选项目。
- 召回一般会线下完成计算,线上根据少量信息完成拉取工作。
- 召回与排序都是推荐算法,但是召回面对的是海量的待选,因此从算法上降低复杂度并从工程上简化线上流程。
类别
无个性化
只使用项目侧特征
- 热门召回、高复购、高潜力、。。。
有个性化
会使用到用户侧特征,往往是只使用一个用户特征,根据这个特征获取对应的候选项目列表。
向量化召回
- 通过用户的向量到库中寻找最近/相似的项目
- 本质上是一个KNN问题
- 工程上会通过一些方式来加速
工具
faiss
由Facebook开发,为稠密向量提供高效相似度搜索和聚类的框架。
- 提供多种检索方法
- 速度快
- 可存在内存和磁盘中
- C++实现,提供Python封装调用。
- 大部分算法支持GPU实现
- 加速搜索
- 通过K-means建立聚类中心
- 将聚类信息写入倒排中,
- 搜索时先查询聚类中心,再查询最近的相似向量
KDtree
将数据递归的在各个维度上二分到超矩形中
Balltree
将数据划分到超球中
Annoy
将数据划分到二叉树上,不使用维度切分,而通过聚类数为2的Kmeans。
NSW
- Navigable Small World graphs:基于图,从任意节点开始,计算自己与近邻节点到目标点的距离,更新为最近的点,依次进行至找到最近的节点。
- 经典思路复杂度较高,可以通过依次随机插入的方式构图,来得到节点连接的高速公路,降低计算量
- HNSW加入了跳表结构做了进一步优化,每一个点都有50%概率进入上一层的有序链表。这样可以保证表层是“高速通道”,底层是精细查找,计算时从上往下依次查找。
协同过滤召回
- 通过历史交互行为计算相似,或先矩阵分解,通过隐向量计算相似;
模型召回
- 模型召回也可以看成是使用多种特征的个性化召回,因为使用到了用户侧特征,但另一方面模型召回又和基本的召回方式有明显地区别。
- 召回要求快,所使用到的模型不能太复杂。
- 经典的召回方式会单独为每一路设置召回数量,在模型召回中不需要也无法单独为每个特征设置数量,这有利也有弊,好处是省去的手动设置的工作,模型自动选择,局限是模型的选择不一定合理,有可能会过于集中在某些范围,使得召回结果不具有多样性,会限制精排的选择空间。
DSSM/双塔
- Deep Structured Semantic Models:深度语义匹配模型,分别为用户/query,和项目/doc等构建一个子网络,子网络输出embedding向量,训练好网络后可以离线保存项目的向量,在线得到用户侧embedding向量,计算相似度,向量化召回;
- 双塔设计的目的是为了快,线上只需要进行内积运算;如果用户侧没有实时特征,则可以直接做成倒排拉链存储,线上只需要查询;
- 内积也可以换成其它合适的距离度量方式,如余弦相似度等;
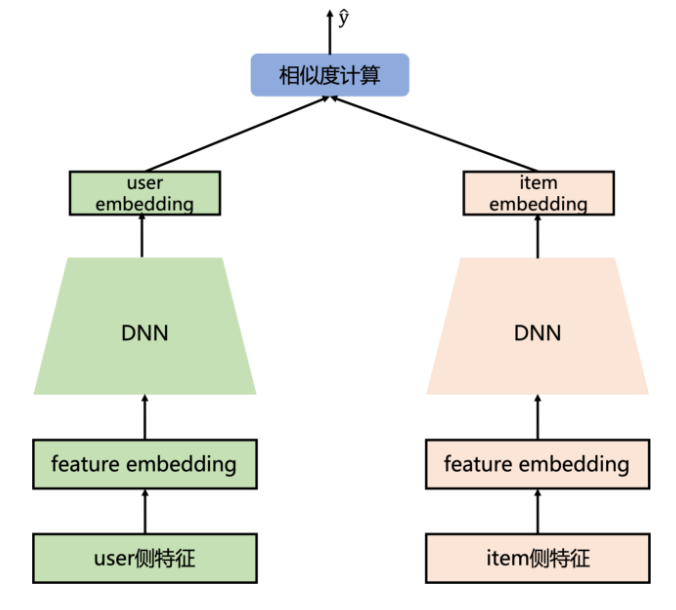
多目标双塔
图神经网络召回
主要是建立用户项目二部图,可以较好地用上协同信息,用户和项目的属性信息用上
基于图的召回
graph embedding
- 将项目序列建图,在图上通过graph embedding的方式得到项目embedding,进而得到相似项目;
- mixed graph-vector model:利用协同过滤CF得到相似最近邻,进而根据最近邻建图,再用graph embedding;
EGES
基础版本
Base Graph Embedding(BGE):以图嵌入的随机游走方式在物品图上捕获物品之间高阶相似性;除了考虑物品的共现,还考虑到了行为的序列信息。
Graph Embedding with Side Information(GES):考虑到稀疏性和冷启物品问题,在图嵌入的基础上,考虑了节点的属性信息。希望具有相似属性的物品可以在空间上相似,即希望通过头部物品,提高属性信息的泛化能力,进而帮助尾部和冷启物品获取更加准确的embedding
Enhanced Graph Embedding with Side Information(EGES):考虑到不同属性信息对于学习embedding的贡献不同,因此在聚合不同的属性信息时,动态的学习不同属性对于学习节点的embedding所参与的重要性权重
流程
- 构建物品图:
- 从行为方面考虑,用户在点击后停留的时间少于1秒,可以认为是误点,需要移除。
- 从用户方面考虑,淘宝场景中会有一些过度活跃用户。本文对活跃用户的定义是三月内购买商品数超过1000,或者点击数超过3500,就可以认为是一个无效用户,需要去除。
- 从商品方面考虑,存在一些商品频繁的修改,即ID对应的商品频繁更新,这使得这个ID可能变成一个完全不同的商品,这就需要移除与这个ID相关的这个商品。
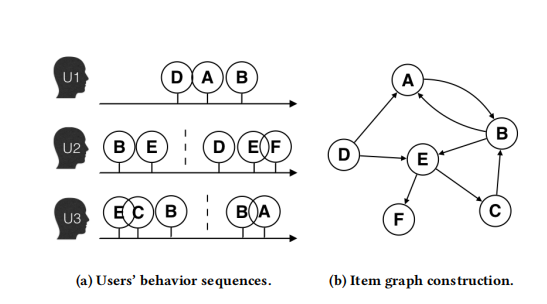
- 图嵌入(BGE):
- 随机游走得到物品序列;
- 通过skip-gram为图上节点生成embedding
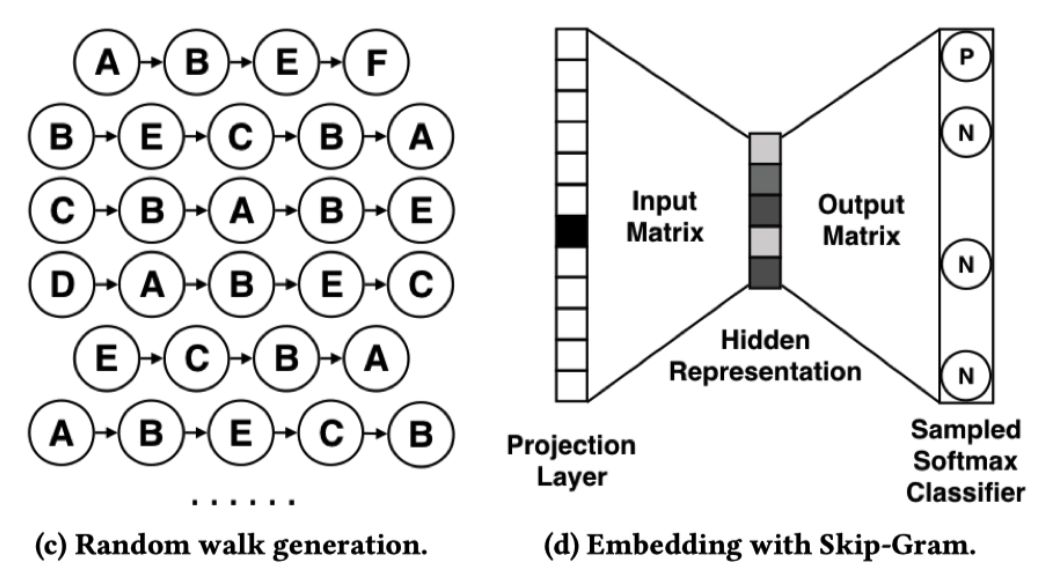
基于side information的图嵌入(GES):
- 为了解决冷启问题,使用side information( 类别,店铺, 价格等)加入模型的训练过程中,使得模型最终的泛化能力体现在商品的side information上。
- 通过side information学习到的embedding来表示具体的商品,$H_v = \frac{1}{n+1}\sum_{s=0}^n W^s_v$,其中,$H_v$是商品 v 的聚合后的 embedding 向量。
增强型EGS(EGES):
- 对各个embedding加权,$H_v = \frac{\sum_{j=0}^n e^{a_v^j} W_v^j}{\sum_{j=0}^n e^{a_v^j}}$
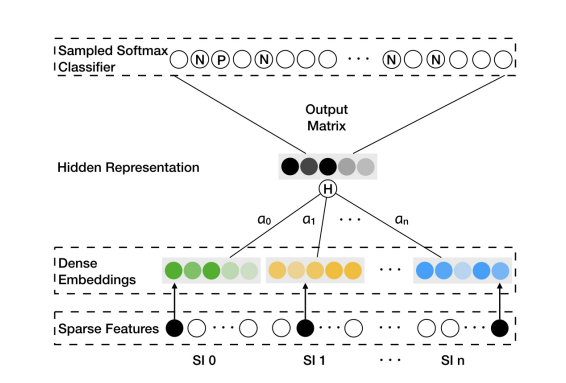
- 损失函数:
- $L(v,u,y)=-[ylog( \sigma (H_v^TZ_u)) + (1-y)log(1 - \sigma(H_v^TZ_u))]$
- y是标签符号,等于1时表示正样本,等于0时表示负样本。$H_v$表示商品 v 的最终的隐层表示,$Z_u$表示训练数据中的上下文节点的embedding。
GraphSAGE
- 通过图卷积GCN的方法聚合邻居信息的方式为给定的节点学习embedding
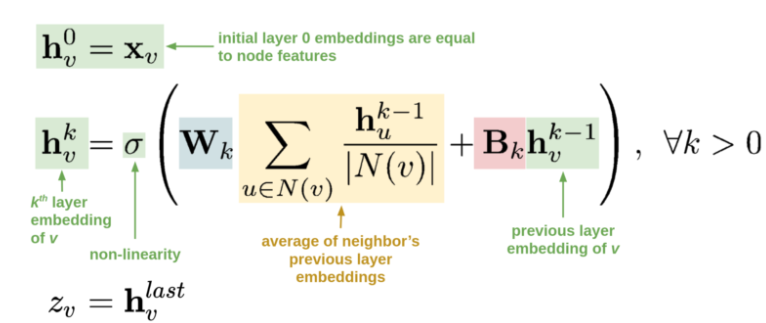
- $h_v^0$表示图上节点的初始化表示,等同于节点自身的特征。
- $h_v^k$表示第k层卷积后的节点表示,其来源于两个部分:
- 第一部分来源于节点v的邻居节点集合$N(v)$,利用邻居节点的第k-1层卷积后的特征$h_u^{k-1}$进行 ($\sum_{u \in N(v)} \frac{h_u^{k-1}}{|N(v)|}$)后,在进行线性变换。这里借助图上的边将邻居节点的信息通过边关系聚合到节点表示中(简称卷积操作)。
- 第二部分来源于节点v的第k-1成卷积后的特征$h_v^{k-1}$,进行线性变换。总的来说图卷积的思想是在对自身做多次非线性变换时,同时利用边关系聚合邻居节点信息。
- 最后一次卷积结果作为节点的最终表示$Z_v$,以用于下游任务(节点分类,链路预测或节点召回)。
- 相比传统的方法(MLP,CNN,DeepWalk 或 EGES),GCN或GraphSAGE的优势:
- 相比于传统的深度学习方法(MLP,CNN),GCN在对自身节点进行非线性变换时,同时考虑了图中的邻接关系。从CNN的角度理解,GCN通过堆叠多层结构在图结构数据上拥有更大的感受野,利用更加广域内的信息。
- 相比于图嵌入学习方法(DeepWalk,EGES),GCN在学习节点表示的过程中,在利用节点自身的属性信息之外,更好的利用图结构上的边信息。相比于借助随机采样的方式来使用边信息,GCN的方式能从全局的角度利用的邻居信息。此外,GraphSAGE通过学习聚合节点邻居生成节点Embedding的函数的方式,更适用于图结构和节点会不断变化的工业场景。
PinSAGE
- 在GraphSAGE的基础上加权采样邻居节点,加权聚合
用户行为序列召回
将用户的行为(点击、购买、收藏等)序列作为模型的输入,输出一个embedding。输出的embedding可以用于向量化召回,输入的位置可以直接使用项目ID加嵌入层,也可以融入项目的side info以缓解冷启动问题。在模型选择上,只要可以提取序列特征的都可以使用,如CNN、RNN、transformer等。
MIND
采用了动态路然由算法能非常自的将历史商品聚成多个集合,每个集合的历史行为进一步推断对应特定兴趣的用户表示向量。这样,对于一个特定的用户,MND输出了多个表示向量,它们代表了用户的不同兴趣。当用户再有新的交互时,通过胶囊网络,还能实时的改变用户的兴趣表示向量,做到在召回阶段的实时个性化。
用户兴趣拆分
上一种方式默认用户交互的项目风格类似,只有这样模型得到的embedding才有意义,如果用户的交互项目分布在多个簇中,那得到的embedding可能和用户的任何交互项目都不相似。
多兴趣召回与用户行为序列召回的主要区别在于输出的位置不是只得到一个向量,而是会有多个向量,分别代表一个兴趣方向。
排序
基础
词汇
- 会话session推荐:基于会话中已知项目,进行next-item预测;
发展脉络
- 记忆:
- LR:一层网络/线性模型,能学到各个特征对于结果的贡献值,但不能学习到特征之间的交叉信息,想要得到交叉关系只能将特征组合成交叉特征。
- 能力有限,只能学到线性关系,能力上限明显,依赖人工组合特征,但是主要特征和重要组合特征已经可以满足很多需求了,因此简单实用。
- 作为baseline模型,进一步优化需要人工组合特征,不适合进一步发展,能力较弱,难以平衡泛化性和模型容量。
- LR:一层网络/线性模型,能学到各个特征对于结果的贡献值,但不能学习到特征之间的交叉信息,想要得到交叉关系只能将特征组合成交叉特征。
- Embedding:细化特征,从单个数据转化为一系列隐式特征,提高特征的表达能力;
- 矩阵分解:将用户和项目表示为Embedding隐向量。
- LR➕Embedding可以看成式学习多个LR然后集成,集成的时候LR的参数设为一致,不一致的部分就是Embedding。
- 向量化召回:通过Embedding隐式的计算相似。
- 特征交叉:增加特征表达能力
- LR:一阶特征或手动组合特征;
- FM:自动学习二阶特征;
- DNN:高阶交叉
- wide&deep:LR低阶记忆+高阶交叉
- Field & Pooling:
- Field:推荐领域的特征往往非常高维、稀疏,所有特征的Embedding如果都直接输入到模型中,参数量将难以承受,且泛化性较差;如果将同一类特征的Embedding进行整合,成为一个Embedding,这样可以大大降低参数量,这样得到的Embedding的信息更加有代表性,也更加具有泛化性。
- Pooling:将同一个Field中的Embedding进行整合的过程,包括mean/max、加权等等。
- YoutubeNet:mean pooling;
- DIN:对用户交互序列进行attention加权pooling
融入对比学习
DHCN:Self-Supervised Hypergraph Convolutional Networks for Session-based Recommendation
- DHCN:双通道超图卷积网络,引入自监督,最大化两个通道学习的会话表示之间的互信息,以改善推荐效果。
- 超图:一个超边可以连接多个不同顶点,对应一个共同的权值,即一条超边对应一个会话。
冷启动
- 新用户、项目的信息比较少,很难学好;
- 新用户没有行为,也很少信息;
- 新项目无反馈历史,也很难得到曝光,召回策略往往也是冷启动不友好;
- 所有的做法都是从各种角度加入信息,有信息是做好的必要条件;常见的是使用side information,以及通过各种非模型的策略。
side information
- 利用属性特征,即ID特征以外,具有泛化能力的特征的embedding对冷启动项进行初始化。
- DropoutNet:通过Dropout机制,促进模型充分学习各种特征,而不是专注在ID特征,以更好的实现冷启动。
- DropoutNet: Addressing Cold Start in Recommender Systems. NeurIPS2017.
- MetaEmbedding:用一个模型利用其它特征来初始化ID特征的embedding。
- Warm Up Cold-start Advertisements: Improving CTR Predictions via Learning to Learn ID Embeddings. SIGIR2019.
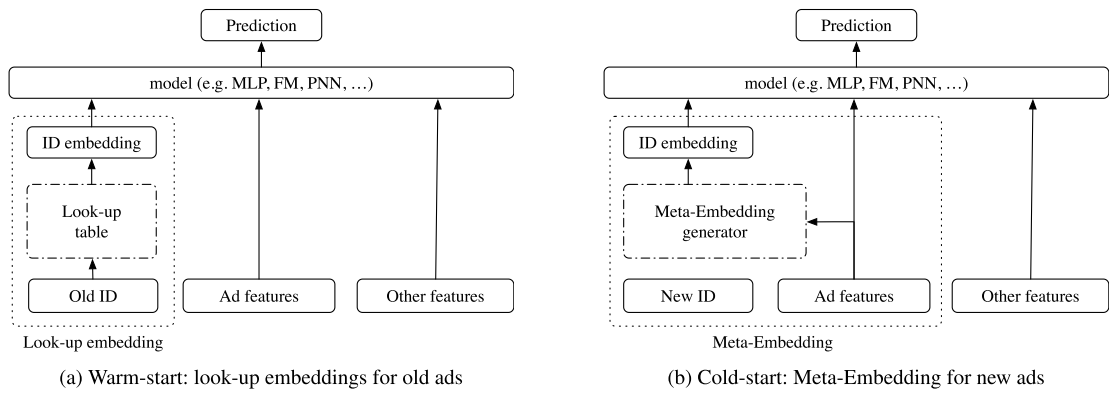
- Warm Up Cold-start Advertisements: Improving CTR Predictions via Learning to Learn ID Embeddings. SIGIR2019.
- Meta Warm Up Framework:考虑到冷启动商品与非冷启动商品的分布不同(有无/多少交互的用户/项),加入对应的结构,使得学到的分布更加准确。
- Learning to Warm Up Cold Item Embeddings for Cold-start Recommendation with Meta Scaling and Shifting Networks. SIGIR2021.
.jpg)
- Learning to Warm Up Cold Item Embeddings for Cold-start Recommendation with Meta Scaling and Shifting Networks. SIGIR2021.
- Airbnb Word2vec:不使用属性的embedding,而是使用每个属性得到最近邻项目,根据最近邻项目的embedding合成新项目的表示;
- DropoutNet:通过Dropout机制,促进模型充分学习各种特征,而不是专注在ID特征,以更好的实现冷启动。
- 知识图谱:从图谱中挖掘信息。
- 。。。
- Knowledge-aware Graph Neural Networks with Label Smoothness Regularization for Recommender Systems. KDD2019.
- 。。。
- 跨领域推荐:一个领域信息丰富,另一个领域信息匮乏,可以将其它领域的信息用于辅助。
- 基于映射的方法:学习一个从一个领域到另一个领域的映射。
- Cross-Domain Recommendation: An Embedding and Mapping Approach. IJCAI2017.
- Transfer-Meta Framework for Cross-domain Recommendation to Cold-Start Users. SIGIR2021.
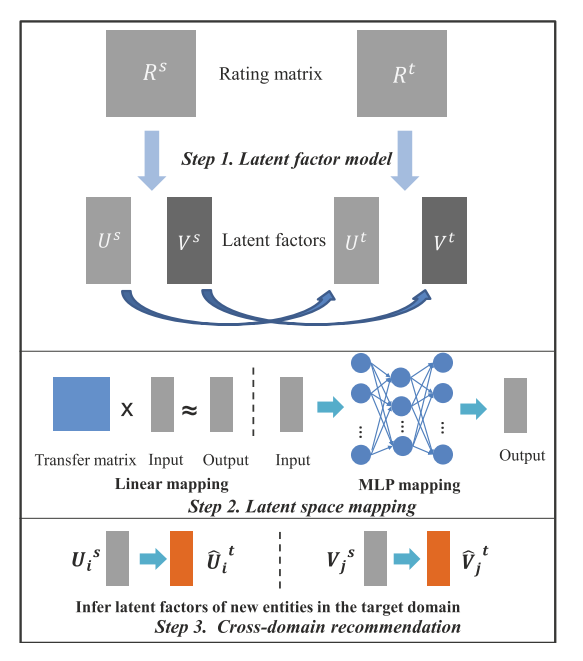
- 基于映射的方法:学习一个从一个领域到另一个领域的映射。
- 多行为推荐:用户可能没有购买,但是有点击、收藏等行为,可以使用这些信息辅助
- 。。。
- Multi-behavior Recommendation with Graph Convolutional Networks. SIGIR2020.
- Modeling the Sequential Dependence among Audience Multi-step Conversions with Multi-task Learning in Targeted Display Advertising. KDD2021.
- 。。。
交互数据
在有了一定的交互数据后就可以利用交互数据进行冷启动。
Explore & Exploit
- Exploit:通过已经探明的兴趣进行推荐
- Explore:通过与已有兴趣无关的逻辑推荐,探索用户兴趣
Bandit
- 臂:可能的选择;
- 回报:做选择后得到的奖励;
- 环境:影响每个选择的因素,在推荐中不同的用户和其它实时特征都是环境;
- 思路:确定高收益和尝试次数比较少(不确定性高)的选择更加容易被选择;
汤普森采样算法
- 认为每个用户在每个选择上的收益概率符合贝塔分布,当尝试次数较小时,分布比较发散,容易被探索,当尝试次数变多时,分布变得集中,是否被选中变得更加确定;
UCB算法
- Upper Confidence Bound:置信区间上界,每个臂的得分由两部分组成,收益均值和不确定性,尝试次数越少,不确定性越高;即平均收益越高,尝试次数越少的臂越容易被选择;
LinUCB算法
- 不只是使用单个用户的尝试次数来获得收益均值和上界,而是通过用户特征来学习,每一个选择有一套参数,参数与输入用户的特征共同得到;
- 相比UCB,参数量更少,收敛更快,泛化性更好;
- 当选择的数量较少时,可以每个选择一套参数,当选择的数量过多时,可以引入选择的特征并共享参数;
**Epsilon 贪婪算法###
- $p$是$(0,1)$之间的一个较小的数,每次以概率$p$随机选择一个臂,同时以概率$1-p$选择目前收益最高的选择;
- $p$越小就越保守,越大则越激进;



